cm3060 Topic 07: Information Extraction
Main Info
Title: Information Extraction
Teachers: Tony Russell-Rose
Semester Taken: October 2021
Parent Module: cm3060 Natural Language Processing
Description
Covers the application of NLP to extract structured information from unstructured text. Includes POS tagging, relation extraction, and named entity recognition (NER).
Assigned Reading
Supplementary Reading
Related Jurafsky Manning Lectures
Introduction to Information Extraction, NER, and Sequence Classification
See also Jurafsky Manning Lecture Summaries: Topic 08 Information Extraction
Introduction to Relation Extraction
See also Jurafsky Manning Lecture Summaries: Topic 09 Relation Extraction
Part of Speech Labeling
See also Jurafsky Manning Lecture Summaries: Topic 11: POS Tagging
UoL Lecture Summaries
Introduction to Information Extraction
Information extraction is the task of making the implicit structure of information in natural language explicit.
Typically factual information.
You can also think of it from a data model point of view, you’re transforming strings to relations.
Discusses some use cases - from scientific literature mining to extracting dates from an email.
Divides information extraction into sub-tasks:
Named Entity Recognition
He includes in NER not just labeling the tokens, but resolving them to a canonical database representation.
Relation Extraction
how do the entities we’ve extracted relate to each other?
Event Extraction
Identify specific events or episodes to reconstruct a timeline
Event coreference
Coreference resolution on events
Temporal event expression extraction
trying to find out when the events actually occurred.
Reviews the standard sets of relations from ACE to UMLS, all from Jurafsky Manning Lecture Summaries: Topic 08 Information Extraction
Introduction to Relation Extraction
Four main categories:
1. Handwritten patterns
Uses the same example as Jurafsky Manning Lecture Summaries: Topic 09 Relation Extraction
High precision, low recall, not scalable, domain specific.
2. Supervised Learning
Follow the standard ML workflow. Includes the idea of using a binary classifier first to see if any relation exists.
Can use neural approaches, eg a pre-trained encoder like BERT which is fine-tuned.
High accuracy, domain specific, but expensive and brittle.
3. Semi-supervised learning
Covers bootstrapping - start with seed relations, find some example sentences, generalize the context and use them to find new seeds.
Also covers distant supervision. Create lots of noisy patterns from a large database of seed tuples, then combine them into a supervised classifier.
Distant supervision avoids the issues of semantic drift of bootstrapping, but needs existing DB and has relatively low precision.
4. Unsupervised or Open Relation Extraction
No labelled data.
We run a POS tagger and entity chunker over each s.
We find the longest phrase that starts with a verb (w)
Find nearest NPs to the left (x) and right (y)
Assign a confidence to relation r = (x,w,y).
Relations are stored if they occur with at least N arguments.
This is flexible, but the output needs to be mapped to some canonical form.
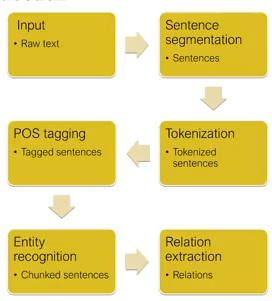
Shows a standard model for an IE pipeline:
POS Tagging and IE with NLTK
Switches to practical demos of POS tagging with NLTK. You tokenize it, apply a pos tagger
Next video looks at IE with NLTK, walking through a basic pipeline.
Chunking
Looks at chunking, the identification of meaningful chunks, a simplistic parse essentially.
Walks through constructing a simple grammar from POS tags, and builds up more complex grammars.
Chinking is the reverse, so we define patterns we want to exclude from a chunk pattern.
Introduces BIO tags - beginning, inside, and outside tags that are commonly used in chunking and NER.
Next video switches from NLTK to Spacy and shows the noun chunk API there, accessed through doc.noun_chunks
Final video looks at the NER API in Spacy. Includes LAW as a category of entities which is ‘Named documents made into laws’. Entities can be accessed through the doc.ents iterator when the text is parsed.