cm3060 Topic 08: Information Retrieval
Main Info
Title: Information Retrieval
Teachers: Tony Russell-Rose
Semester Taken: October 2021
Parent Module: cm3060 Natural Language Processing
Description
In this topic we explore how NLP ideas are used in constructing search engines and study some of the foundational models for representing text.
Assigned Reading
Related Jurafsky Manning Lectures
17: Information Retrieval
See also Jurafsky Manning Lecture Summaries: Topic 17: Information Retrieval
17.1: Introduction to Information Retrieval
17.2: Term-Document Incidence Matrices
17.4: Query Processing with an Inverted Index
17.5: Phrase Queries and Positional Indexes
18: Ranked Retrieval
See also Jurafsky Manning Lecture Summaries: Topic 18: Ranked Retrieval
18.1: Introducing Ranked Retrieval
18.2: Scoring with the Jaccard Coefficient
18.3: Term Frequence Weighting
18.4: Inverse Docuemnt Frequency Weighting
18.7: Calculating TF-IDF Cosine Scores
18.8: Evaluating Search Engines
Lecture Summaries
Boolean Retrieval
Steps back to introduce the task of IR.
IR is the task of finding documents in a collection that satisfy an information need. Typically we are dealing with unstructured information.
Use cases include professional search, enterprise search, web search, site search.
Presents three models of IR:
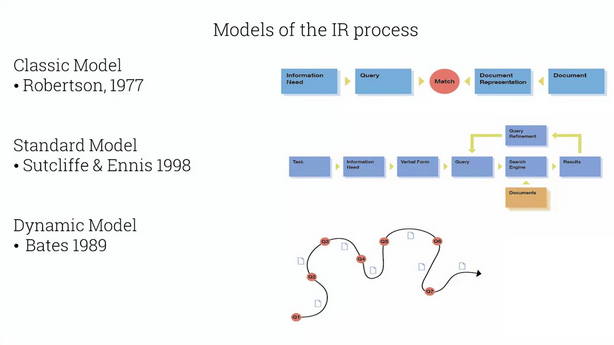
IR is not linear, and the accumulation of insights along the way is often the goal. So TRR prefers the dynamic model.
Then recaps the lectures of JM from Jurafsky Manning Lecture Summaries: Topic 17: Information Retrieval covering 17.1 through 17.4 (does not cover phrase queries or positional indexes).
Ranked Retrieval
Boolean search gives control through precise queries, reproducible results, and transparency. But users don’t want to learn complex boolean queries, so in many search contexts ranked retrieval has won out.
Runs through the lectures in Jurafsky Manning Lecture Summaries: Topic 18: Ranked Retrieval. Covers tf, idf, tf-idf.
Vector Space Model
Covers the JM lecture 18.6 almost exactly, for a summary see Jurafsky Manning Lecture Summaries: Topic 18: Ranked Retrieval
Representing Documents
Walks through vectorizing with skl’s CountVectorizer model.
Term Weighting with TF.IDF
Uses skl’s TfidfVectorizer model.
Semantic Search
Discusses query search expansion as a solution to vocabulary mismatch.
Uses whoosh docs here to build a search engine.
Uses this model repository to get the pretrained embeddings.
Uses gensim to get similar words to the search query, and then uses them in the search too, expanding the original query with a boolean or with the related terms.
Lab Summaries
Lab has you play around with TRR’s ‘2D search engine’: https://app.2dsearch.com/