cm3060 Topic 09: Chatbots and Dialogue Systems
Main Info
Title: Chatbots and Dialogue Systems
Teachers: Tony Russell-Rose
Semester Taken: October 2021
Parent Module: cm3060 Natural Language Processing
Description
In this topic we study the fundamental principles of human conversation and learn how to apply them in building chatbots and dialogue systems.
Assigned Reading
Additional Reading
Lecture Summaries
Properties of Human Conversation
A dialogue is a sequence of turns (of varying length). We need to know when to stop talking (detect an interruption) and when to start talking (detect completion of a turn).
Each utterance is a kind of action performed by the speaker, or speech act.
In constatives the speaker commits to some proposition, eg claim, confirm, deny.
In directives we get the addressee to do something, eg ask forbid, invite
In commissives we commit to some future course of action, eg promise, plan vow.
In acknowledgements we express reaction to some action, eg apologize, greet, thank.
Dialogue is a collective act characterized by cooperation. It depends on common ground between the participants, established through grounding.
It’s established by acknowledging that the hearer has understood the speaker. An analogous principle in HCI is system feedback. It could be explicit or implicit.
Dialogues can have a nested structure, where dialogues contain sub-dialogues. This might entail repairing a dialogue through correction or clarification where it has gone awry.
A key concept in dialogue is initiative.
Dialogue may be controlled by one participant, which would be single initiative. Most dialogue is mixed initiative where initiative goes back and forth.
Mixed initiative is a difficult system design problem. It’s simpler to offer either user initiative (eg search engines), or system initiative eg IVR/call systems.
Dialogues rely on inferences and conversational implicature.
Chatbots
Chatbots are simple dialogue systems for extended conversations. As opposed to task-oriented dialogue systems. Mainly used for entertainment value.
There have been rule based architectures - Eliza, Parry. Or corpus based - where we mine large datasets and use IR techniques or Encoder-decoder systems.
Presents Eliza (Wiezenbaum 1966). Explains the pattern matching and generation systems, along with fallback to previous topics.
Then presents corpus based approaches. Here we train on a corpora of human-human conversations, like call-centre transcripts or movie dialogues. We might pre-train on larger language corpora, or exploit live-usage data.
Confidence metrics are needed. Then responses are generated via IR or generation methods.
In IR methods we take the user’s utterance as a query, then find the highest matching response from our corpus, using classic vector space IR methods.
In Neural IR approaches we have a bi-encoder (one for the query, one for the response), and take the dot product of the vectors. Here we can consider all of the prior conversation.
In generator methods we treat it as a sequence to sequence task, analogous to translation. This is often conservative, so we need to find ways of introducing diversity in the algorithm.
More complex techniques include exploiting external knowledge bases, and query expansion techniques. Also hybrid architectures, where we use templates, regexes, and classifiers.
Task Based Dialogue Systems
In task-based dialogue systems we are trying ot help the user achieve some goal, eg book a flight. A significant early example was GUS which was travel-oriented.
Two key ideas in GUS are frames, structured knowledge representation for user intent; and slots, attribute-value pairs that reside in the frames.
The process becomes one of asking questions, filling slots, and then performing relevant actions (via rules). We can fill multiple slots with one utterance. Some tasks require multiple frames.
This gives us three core tasks in NLU:
Domain classification
Intent determination (eg book/cancel/confirm a reservation)
Slot filling (assign entities to slots)
For example if we receive “Wake me tomorrow at 7”, we can interpret the domain as alarm-clock, the intent as set-alarm, and the time (slot) as tomorrow at 7.
Matching can be done using rules, eg semantic grammars, regexes. This is typically high precision but expensive and difficult to scale, but low recall.
A more sophisticated approach is dialogue-state architecture. This uses ML as well as rule-based formalisms, and uses the notion of dialogue acts. Presents the following diagram:
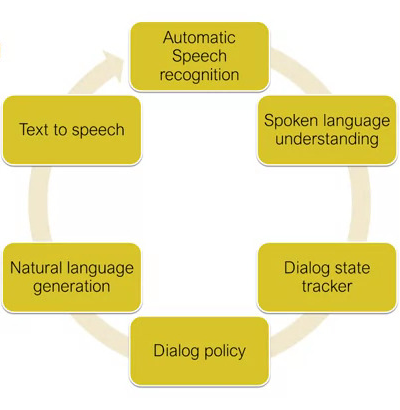
The state tracker keeps track of the most recent act and all the slots and fillers.
The policy defines what the system should do/say next.
The generation creates the response based on templates/context.
Gives quite a confusing introduction to dialogue acts and the ML approaches to building these architectures.
In practice they are often bootstrapped, using GUS-style rules. We start from hand-annotated rules and a test set.
New utterances are labelled using rules to produce new tuples. Classifier is trained on the tuples and evaluated on the test set.
Design and Evaluation
Design is an interactive process. Our product is interactive so we draw from HCI to shape the process.
We can adopt a user-centred design process. We study users and tasks, build simulations and prototypes, and iteratively test the design on users.
We can use wizard-of-oz methods to simulate interactions. We put a human in the loop to emulate the system behaviour to refine the design before we build them.
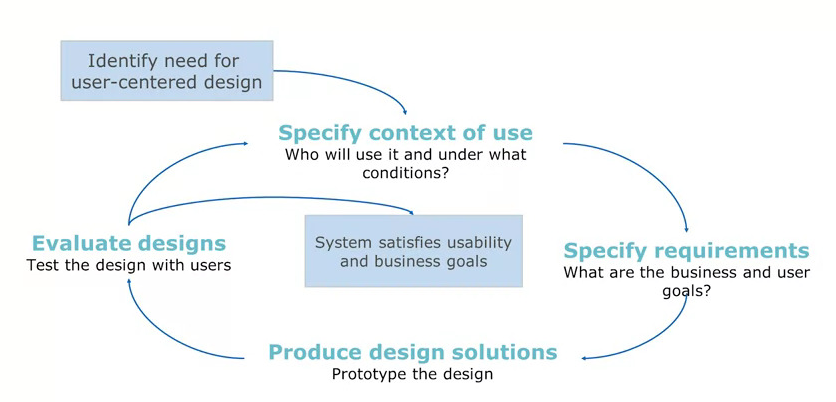
There is an ISO standard for human centred design for interactive systems, ISO 9241-210. Illustrated like this:
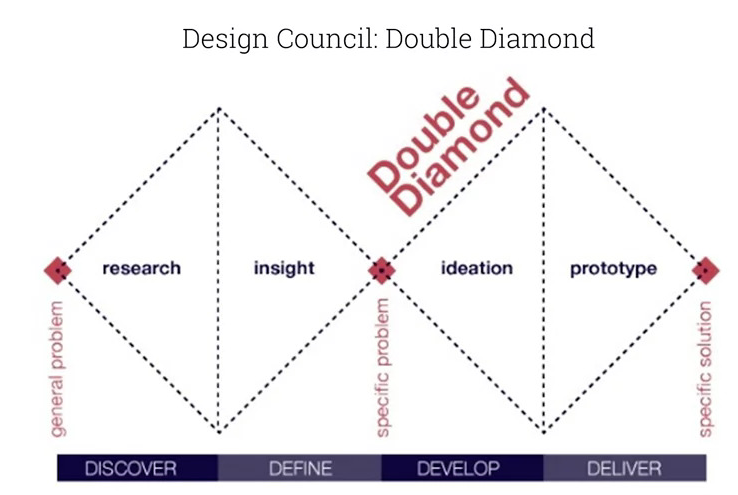
There is also the Design Council’s Double Diamond approach:
For evaluation, we can use BLEU, ROUGE etc but they aren’t a good proxy for chatbots. We need to use manual approaches: participant evaluation, or observer evaluation.
We’d score the interaction along dimensions like cogency, fluency, listening etc.
What about task-based systems? We could measure task success, did the user complete the task? With what costs? User satisfaction or slot error rate can be measured.
Practicals
Week 18 lectures walk through building chatbots in NLTK and Rasa. They perform really badly.
The Rasa config process rests on several yaml files:
config.ymlspecifies policies for training the model.domain.ymllists the possible intents that the bot can represent, and the bot’s responses.nlu.ymllists how the intents are recognized, patterns to match.rules.ymllists hard coded rules that map intent to response.stories.ymllists coherent conversational paths, which the bot can recognize and follow.