Chollet: Chapter 01: What is Deep Learning?
Metadata
Title: What is Deep Learning?
Number: 1
Book: Chollet: Deep Learning
Key Quotes
the central problem in machine learning and deep learning is to meaningfully transform data: in other words, to learn useful representations of the input data at hand - representations that get us closer to the expected output.
Learning, in the context of machine learning, describes an automatic search process for data transformations that produce useful representations of some data, guided by some feedback signal - representations that are amenable to simpler rules solving the task at hand.
that’s what machine learning is, concisely: searching for useful representations and rules over some input data, within a predefined space of possibilities, using guidance from a feedback signal. This simple idea allows for solving a remarkably broad range of intellectual tasks, from speech recognition to autonomous driving.
Deep Learning is a specific subfield of machine learning: a new take on learning representations from data that puts an emphasis on learning successive layers of increasingly meaningful representations.
These are the two essential characteristics of how deep learning learns from data: the incremental, layer-by-layer way in which increasingly complex representations are developed, and the fact that these intermediate incremental representations are learned jointly, each layer being updated to follow both the representational needs of the layer above, and the needs of the layer below. Together, these two properties have made deep learning vastly more successful than previous approaches to machine learning.
AI, Machine Learning, and Deep Learning
The intro presents AI, ML, and DL as nested concentric circles.
AI
It describes AI as “the effort to automate intellectual tasks normally performed by humans”, so it is a general field that encompasses ML and DL, but includes other approaches to that effort. “until the 1980s, most AI textbooks didn’t mention ‘learning’ at all!". It describes symbolic AI as the attempt to “handcraft a sufficiently large set of explicit rules for manipulating knowledge stored in explicit databases”. This approach proved intractable for complex, fuzzy problems like machine translation.
Machine Learning
It presents ML as a ‘new programming paradigm’ in which a system is trained rather than explicitly programmed:
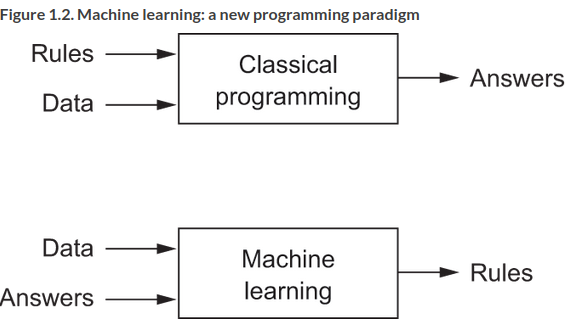
ML is now “the most popular and successful subfield of AI”. It is related to statistics, but differs in important ways (like how medicine can’t be reduced to chemistry). It deals with large, complex datasets, and often exhibits comparatively little mathematical theory. It is more an engineering discipline, driven by empirical findings and reliant on software and hardward advances.
To do ML we need three things: input data points, examples of the expected output, and a way to measure whether the algorithm is doing a good job (used as a feedback signal to adjust the way the algorithm works).
As mentioned in the key quotes, we need to learn useful representations of the data. What’s a representation? A way to look at data, eg the RGB or HSV representation of colour. Problems that might be difficult with one representation are easier with another.
Concretely, say we want to distinguish white and black points in the following:
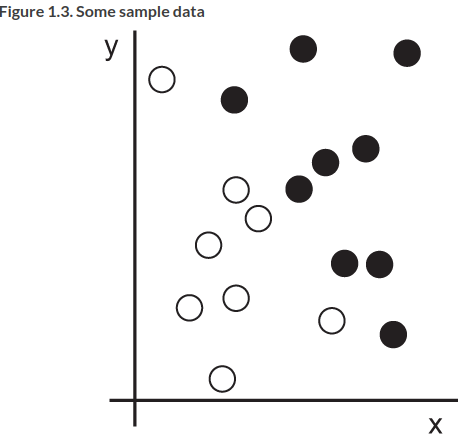
We want a representation that makes our job as easy as possible. One way would be to do a coordinate change:
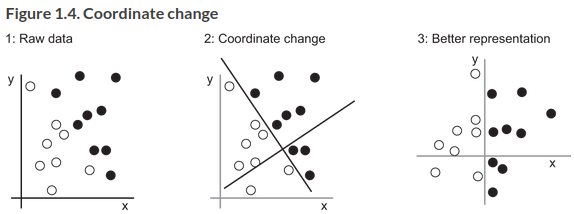
Now we have a really simple rule, black points have \(x > 0\), and vice versa. We can do this by hand for such a simple problem, but for a more complex one it becomes hard very quickly. Take the example of recognizing handwritten characters.
Could we automate it? Yes, then we’re doing ML, see the key quote above. The transformations migth be coordinate changes, linear projections, translations, nonlinear operations. Crucially, ML algorithms aren’t usually creative in finding these transformations, they are searching through a predefined set of operations called a hypothesis space, eg the space of all co-ordinate changes.
Deep Learning
So what makes Deep Learning different from ML as described above? As per the key quote above, the ‘deep’ isn’t a reference to any kind of deeper understanding, it’s the idea of successive layers of representations. How many layers contribute to the model is the depth of the model. It could have been called layered representation learning or hierarchical representations learning. A modern model might learn tens or hundreds of layers, and they’re all learned automatically from exposure to training data. If there are only a couple of layers involved in a representation we might call it shallow learning.
These representations are almost always learned via models called neural networks, structured in layers stacked on top of each other. The term comes from neurobiology, which provided initial inspiration, but these aren’t models of the brain. It’s a mathematical framework for learning useful representations from data.
What do the representations look like? An example of a four layer network transforming a digit to recognize it:
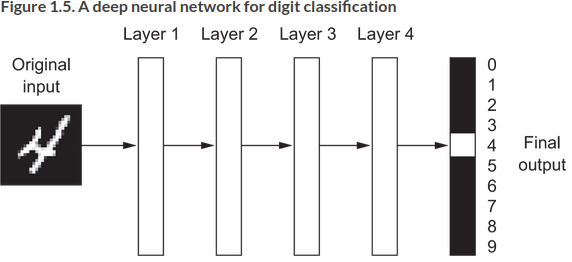
The process involves information distillation, such that the infromation is increasingly purified, useful to some task:
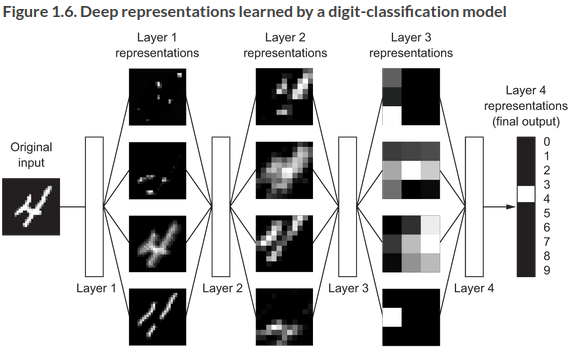
That’s all DL is, a multistage way to learn data representations. But scaled up, it looks like magic.
How Deep Learning Works
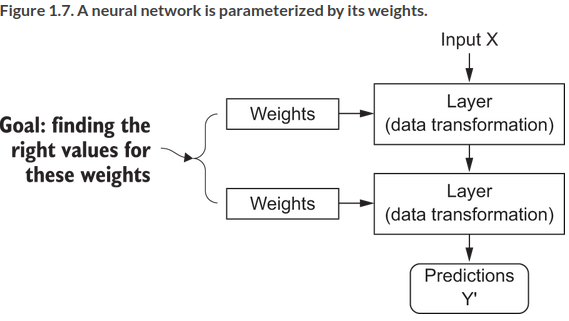
So deep neural nets map inputs to targets via a deep sequence of data transformations (layers), which are learned by exposure to examples.
The specification of what a layer does is stored in the layer’s weights, a set of numbers. The layer is parameterized by its weights, weights are also called parameters of a layer. learning means finding a set of values for the weights of all layers in a network, so that inputs are mapped correctly to targets. But a deep network might have tens of millions of parameters, and modifying one will affect the behaviour of others. How do we do learn them?
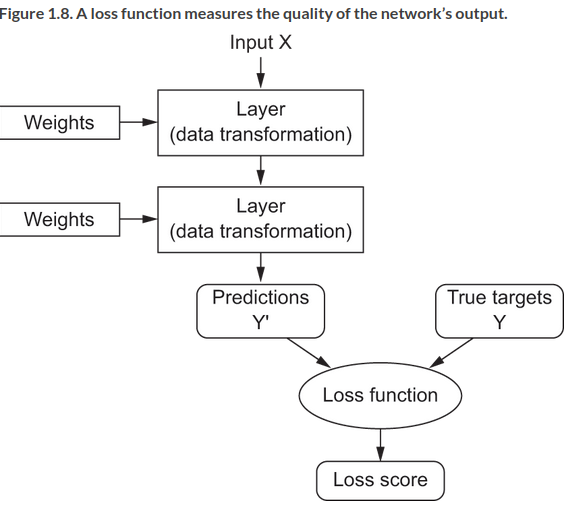
You need to measure how far the output is from what you expect. This is the job of the loss function, aka objective function or cost function of the network. It takes the predictions of the network, the true target, and computes a distance score, like this:
The trick is to use this score as a feedback signal to adjust the value of the weights a bit to try to lower the score. This is the job of the optimizer which implements the backpropogation algorithm, the main algorithm in DL. So the process looks like this:
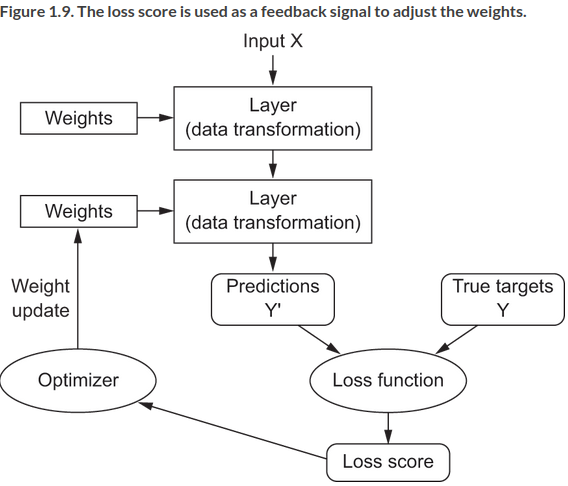
The weights are initially assigned random values, so the loss score is high, then they are adjusted during a training loop, typically tens of cycles over thousands of examples, until the loss function is minimized.
Deep learning has achieved a lot recently, revolutionizing fields like speech recognition, NLP and more. There is short term optimism, don’t believe it! But the long term prospects are good.
A history of Machine Learning
The chapter then gives a history of ML before the latest DL boom. It describes distinct phases:
Probabilistic Modelling
Probabilistic modeling is the application of the principles of statistics to data analysis. It was one of the earliest forms of machine learning, and it’s still widely used to this day. One of the best-known algorithms in this category is the Naive Bayes algorithm.
The ‘naivety’ refers to assuming that all features in the data are independent. A closely related model is the logistic regression algorithm, actually a classification algorithm, which is still useful due to its simplicity and versatility.
Early Neural Networks
Early neural network approaches have been superseded now. The early ideas were investigated in the 50s, but we missed an efficient way to train large networks. The missing piece was the rediscovery of backpropagation - a way to train chains of parametric operations using gradient descent optimization - and applied it to neural nets. Le Cun combined backpropagation with convolutional neural nets to develop a system for classifying digits, which was the first practical application.
Kernel Methods
Kernel methods are a group of classification algorithms, the best known of which is support vector machines. SVM works by finding “decision boundaries” separating two classes. The data is first mapped to a high-dimensional representation where the decision boundary can be expressed as a hyperplane. Then a good decision boundary is computed by trying to maximize the distance of the hyperpale and the closest data points from each class, a step called maximizing the margin. This allows it to generalize well to new samples.
Mapping to a high dimensional space can often become intractable. This is where the key method, the kernel trick comes in. Here you don’t have to explicitly compute the co-ordinates of your points in the new space, just the distance between them using a kernel function. This function maps any two points in your initial space to the distance between them in your target representation space, bypassing computing the new representation explicitly. The kernel functions are hand-crafted, only the hyperplane is learned.
SVMs were massively popular, they showed great results for the time and were mathematically grounded. But they were hard to scale to large datasets, and required manual feature extraction (or feature engineering) for many domains, like images.
Decision Trees, Random Forest, and Gradiant Boosting Machines
Decision trees let you classify input data or predict output values given inputs. DTs learned from data were a focus during the 2000s and by 2010 were often preferred to kernel methods.
In particular, the random forest algorithm introduced a robust and practical take on the DT approach. It builds a large number of specialized decision tree and combines their outputs.
Random forests are applicable to a wide range of problems - you could say they’re almost always the second-best algorithm for any shallow machine-learning task.
Gradient boosting largely took over from random forests from 2014 or so. It also ensembles weak prediction methods (DTs) using gradient boosting as a way to improve nay ML model by iteratively training new models to address the weak points of the previous model. Applied to DTs, gradient boosting produces models that strictly outperform RFs most of the time. “It may be one of the best, if not the best, algorithm for dealing with nonperceptual data today.”
Back to Neural Networks
In the 2010s several groups focusing on neural nets started to make major breakthroughs on challenges like ImageNet (Krizevsky and Hinton).
Since 2012, deep convolutional neural networks (convnets) have become the go-to algorithm for all computer vision tasks; more generally, they work on all perceptual tasks… At the same time, deep learning has also found applications in many other types of problems, such as natural language processing. It has completely replaced SVMs and decision trees in a wide range of applications.
Why Deep Learning?
Beyond the performance wins, DL took off because it makes problem-solving much easier by automating the most crucial step, feature engineering.
Feature engineering for complex problems was a pain. Couldn’t we just apply shallow methods repeatedly to emulate DL?
In practice, there are fast-diminishing returns to successive applications of shallow-learning methods, because the optimal first representation layer in a three-layer model isn’t the optimal first layer in a one-layer or two-layer model.
DL allows a model to learn the layers jointly or greedily rather than in succession. This is the major factor behind its success (see key quote).
State of the art
From 2016 to 2020, the entire machine learning and data science industry has been dominated by these two approaches: deep learning and gradient boosted trees. Specifically, gradient boosted trees is used for problems where structured data is available, whereas deep learning is used for perceptual problems such as image classification.
For gradient boosted trees, check out Scikit-Learn, XGBoost, or LightGBM. For deep learning check out Keras and Tensorflow. You’ll need to know the three libraries Scikit-Learn, XGBoost and Keras in particular to work in current ML.
The chapter reviews why now? Looking at advances in hardware, algorithmic design, data scales etc that make DL flourish. It also argues DL is here to stay, and any successor will have to inherit DL’s simplicity and re-usability. It will still take many years to see DL’s potential really hit home.