Jurafsky Martin Chapter 18: Word Senses and WordNet
Metadata
Title: Word Senses and WordNet
Number: 18
Core Ideas
Words are ambiguous, the same word can be used to mean different things. We say that words with multiple meanings is polysemous. A sense or word sense is a discrete representation of one aspect of the meaning of a word.
Word senses may have relations for example there is an IS-A relation between dog and mammal and a part-whole relation between engine and car. Knowing the relation between two senses can play an important role in tasks involving meaning.
Consider the anonymy relation, where word senses are opposite to each other. Distinguishing antonyms is important, but Static Embeddings can often confuse them, often one of the closest words in embedding space to a word is its antonym. Thesauruses like WordNet that represent such relations can help.
Word Sense Disambiguation (WSD) is a longstanding and critical task in NLP, for tasks like machine translation, information retrieval, and QA.
Defining Word Senses
We can denote word senses through superscripts after the words, eg \(\textrm{mouse}^1\) and \(\textrm{mouse}^2\). How do we define them? The intuition of static embeddings is that you can define the meaning of a word by its co-occurrences. But that doesn’t help us define the meaning of a word sense. This is remedied by contextual embeddings like BERT, which are at the heart of modern algorithms for word sense disambiguation.
To start, think of how a dictionary defines senses, through glosses. Glosses for bank might include “sloping land (especially the slope beside a body of water)” or “financial institution that accepts deposits and channels the money into lending”.
These glosses are not formal, and are often circular. They might be self-circular (eg right “nearer the right hand than the left”) or mutually recursive (eg red “the colour of blood”, blood “the red liquid that circulates…"). These are useful for people because we already have a rough sense of meaning.
But these glosses are also useful for computational tasks. A gloss is just a sentence, and from sentences we can compute sentence embeddings. Dictionaries often give example sentences, and these are useful for building sense representation.
Thesauruses also suggest or define relations between senses, which can be helpful. EG from the definition above it’s clear that right and left are similar but in opposition to each other. Given a sufficiently large database of explicit relations (like WordNet) many applications are capable of performing sophisticated semantic tasks around word senses.
Dictionaries give discrete lists of senses, but embeddings offer a continuous high-dimensional model of meaning that doesn’t divide up into discrete senses. So creating a thesaurus depends on the criteria for deciding when the different uses of a word should be represented by discrete senses. Perhaps they have different truth conditions, different syntactic behaviour, and independent sense relations, or antagonistic meanings. Eg “He served as US ambassador…” has a distinctive syntactic structure of “serve as NP” from “They serve coffee”.
We often don’t need as fine-grained a set of word senses as dictionaries in computational tasks, so we’ll cluster them.
Relations between Senses
Synonymy
As mentioned in Jurafsky Martin Chapter 06: Vector Semantics and Word Embeddings where two word senses of two different words are near identical they are synonyms (eg sofa/couch, vomit/throw up, car/automobile).
In truth it is the senses that have the relationship rather than the words. Consider big and large. We cannot substitute in “his big brother” without changing the meaning, as big has a sense that large does not (older). So some senses of big and large are synonymous but others are not.
Antonymy
Antonyms are words with opposite meanings like long/short big/little, fast/slow etc. They might define binary opposites, or be at opposite ends of some scale. Reversives define change of movement in opposite directions (eg rise/fall). They are otherwise very similar, sharing almost all other aspects of meaning except the one aspect on which they differ completely. So distinguishing synonyms from antonyms automatically is difficult.
Taxonomic Relations: Hypernymy
A word (or sense) is a hyponym of another word if the first is more specific, denoting a subclass of the other. eg car is a hyponym of vehicle. Conversely vehicle is a hypernym of car.
As these terms are so similar, and easily confused we might use subordinate and superordinate instead.
We might think of these relations in terms of sets (the superordinate class includes all members of the subordinate one), or in terms of entailment: A sense A is a hyponym of B if being an A entails being a B. The IS-A hierarchy captures this hypernym/hyponym structure if A IS-A B, then B subsumes A. Hypernymy is useful for tasks like textual entailment or QA. EG knowing that leukemia is a type of cancer is useful in medical QA.
Meronymy
meronymy is the part-whole relation. A leg is a meronym of a chair, while a chair is a holonym of a leg.
Structured Polysemy and Metonymy
Senses of a word might be related semantically. For example think of “The bank is at the corner of fifth and main”. Here we are talking about the building belonging to the financial institution. This is a common relation (school, hospital, corporation etc). The systematic relationship can be represented as:
BUILDING \(\leftrightarrow\) ORGANIZATION
Metonymy is a type of polysemy where one aspect of a concept or entity is used to refer to other aspects, or the entity itself. Eg when we refer to Downing Street or The White House as the administration whose office is there. Others include “I really love Jane Austen” (AUTHOR \(\leftrightarrow\) WORKS OF AUTHOR).
WordNet
WordNet is the most commonly used resource for sense relations in English. It has 3 separate databases, for nouns, verbs, and adjectives/adverbs. It has c. 120k nouns, 12k verbs, 22k adjectives, and 4k adverbs. Entries have a gloss (dictionary like definition) and a list of synonyms or synset.
We can think of a synset as representing a concept through the word senses that can be used to represent it. Glosses are properties of the synset, so that each word sense in the synset has the same gloss and can be used to express it. So synsets are teh fundamental unit of WordNet entries and participate in most of the lexical sense relations in WordNet.
Each synset is labelled with a lexicographic category, also called supersense which act as coarse semantic categories or groupings which are useful when word senses are too fine-grained. For example here are the categories for nouns:
| Category | Example |
|---|---|
| ACT | service |
| ANIMAL | dog |
| ARTIFACT | car |
| ATTRIBUTE | quality |
| BODY | hair |
| COGNITION | way |
| COMMUNICATION | review |
| FEELING | discomfort |
| FOOD | food |
| GROUP | place |
| LOCATION | area |
| MOTIVE | reason |
| NATURAL EVENT | experience |
| NATURAL OBJECT | flower |
| OTHER | stuff |
| PERSON | people |
| PHENOMENON | result |
| PLANT | tree |
| POSSESSION | price |
| PROCESS | process |
| QUANTITY | amount |
| RELATION | portion |
| SHAPE | square |
| STATE | pain |
| SUBSTANCE | oil |
| TIME | day |
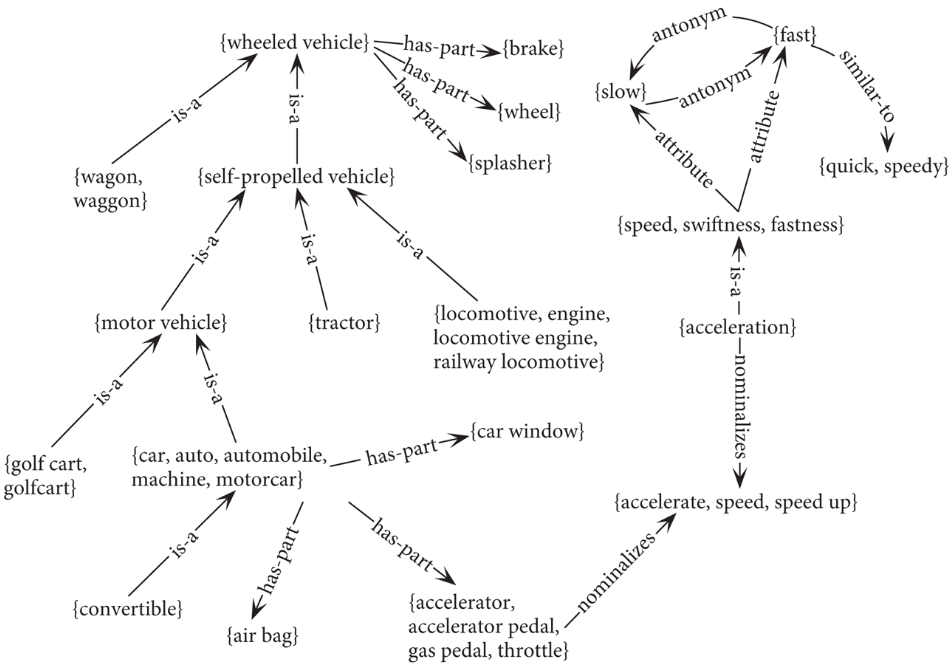
WordNet also represents relations, eg here are some of the noun relations:
| Relation | Also Called | Definition | Example |
|---|---|---|---|
| Hypernym | Superordinate | From concepts to superordinates | breakfast1→meal1 |
| Hyponym | Subordinate | From concepts to subtypes | meal1→lunch1 |
| Instance Hypernym | Instance | From instances to their concepts | Austen1 →author1 |
| Instance Hyponym | Has-Instance | From concepts to their instances | composer1 →Bach1 |
| Part Meronym | Has-Part | From wholes to parts | table2 →leg3 |
| Part Holonym | Part-Of | From parts to wholes | course7 →meal1 |
| Antonym | Semantic opposition between lemmas | leader1 ⇐⇒follower1 | |
| Derivation | Lemmas w/same morphological root | destruction1 ⇐⇒destroy1 |
WordNet has two kinds of taxonomic entities: classes and instances, eg San Francisco is an instance of city.
We can see the WordNet taxonomy as a graph:
Word Sense Disambiguation
The chapter then moves on to consider Word Sense Disambiguation a critical NLP problem, discussing approaches to solving the problem with contextual embeddings, and knowledge-based approaches.
Using Thesauruses to Improve Embeddings
Thesauruses have been used to improve static and contextual word embeddings. They can help solve the problem of antonymy where static embeddings treat antonyms as highly similar.
There aret wo families of solutions. The first requires retraining. We modify the embedding training to incorporate thesaurus relations like synonymy, supersenses, antonymy. We can modify the static embedding loss function for example.
The other, for static embeddings, is more lightweight, after the embeddings have been trained we learn a second mapping based on a thesaurus that shifts the embeddings of words such that synonyms (according to the thesaurus) are pushed closer together, and antonyms further apart. This is called retrofitting or counterfitting.
Word Sense Induction
Word Sense Induction or WSI is an unsupervised approach to disambiguation, avoiding the costs of building large corpora in which each word is labeled for sense manually. In WSI the “senses” of each word are created automatically for each word in the training set. Most approaches follow Schutze in using some kind of clustering over word embeddings. In training we use three steps:
For each token \(w_i\) of word w in a corpus, compute a context vector c.
Using a clustering algorithm, cluster these word-token context vectors c into a predefined number of groups or clusters. Each cluster defines a sense of w.
compute the vector centroid of each cluster. Each vector centroid \(\mathbf{s_j}\) is a sense vector representing that sense of w.
We don’t have names or human representations of these senses, we just refer to them as the jth sense of w.
Then to disambiguate a particular token t of w we have another three steps:
Compute a context vector c for t.
Retrieve all sense vectors \(s_j\) for w.
Assign t to the sense represented by the sense vector \(s_j\) that is closest to t.
So all we need now is the clustering algorithm and a distance measure. A frequently used clustering technique in language applications is agglomerative clustering. Each of the N training instances is first assigned its own cluster. New clusters are formed bottom-up through successive merging of the two most similar clusters. The process stops when a specified number of clusters is reached, or a global goodness metric among the clusters is achieved. If this is too expensive due to the number of training instances, random sampling can be used.
Evaluation is typically extrinsic, some attempts have been made to develop intrinsic measures, but nothing is standard yet.