Tunstall et al: Chapter 01: Hello Transformers
Metadata
Title: Hello Transformers
Number: 1
Book: Tunstall et al: Natural Language Processing with Transformers
Introduction
Transformers were introduced in 2017 and have become the de facto standard for tackling a wide range of NLP tasks in academia and industry. Industry uses include google search and GitHub’s Copilot.
Their breakthrough was the combination of several ideas: attention, transfer learning, and scaling up neural networks, all of which were percolating in the research community.
Hugging Face helped popularize transformer models by making them easy to use, train, and share. The chapter introduces both the transformer architecture and the library.
History of Transformers
In 2017 the Google research paper, Attention is all you need -> proposed a new network architecture for sequence modeling, which it called the Transformer architecture.
In parallel work an effective transfer learning method was developed, called Universal Language Model Fine Tuning or ULMFiT and published -> in 2018. This approach pre-trained a language model on a large diverse corpus, and then fine-tuned the model on a (possibly different) target task, such as classification. The fine-tuning could be done with very little data.
Those advances led to the development of two models that combined them, GPT and BERT. These models set new benchmarks for almost every standard NLP task by a wide margin. Essentially the models combine three core elements in their architecture:
The encoder-decoder framework
Attention Mechanisms
Transfer Learning
To understand what’s so novel about this, we’ll look at each in turn.
The Encoder-Decoder Framework
Prior to transformers, LSTMs were the state-of-the-art in NLP. The architectures contain a cycle or feedback loop in the network connections that allow information to propagate from one step to another, so ideal for modeling sequences like language data.
A Recurrent Neural Net (RNN) receives some input \(x_i\), feeds it through a network A and outputs both a value, the hidden state, \(h_i\) and some information back to itself, which it can then use in processing input \(x_{i+1}\). So information from prior steps can be used for output predictions of the current step.
See this depiction:
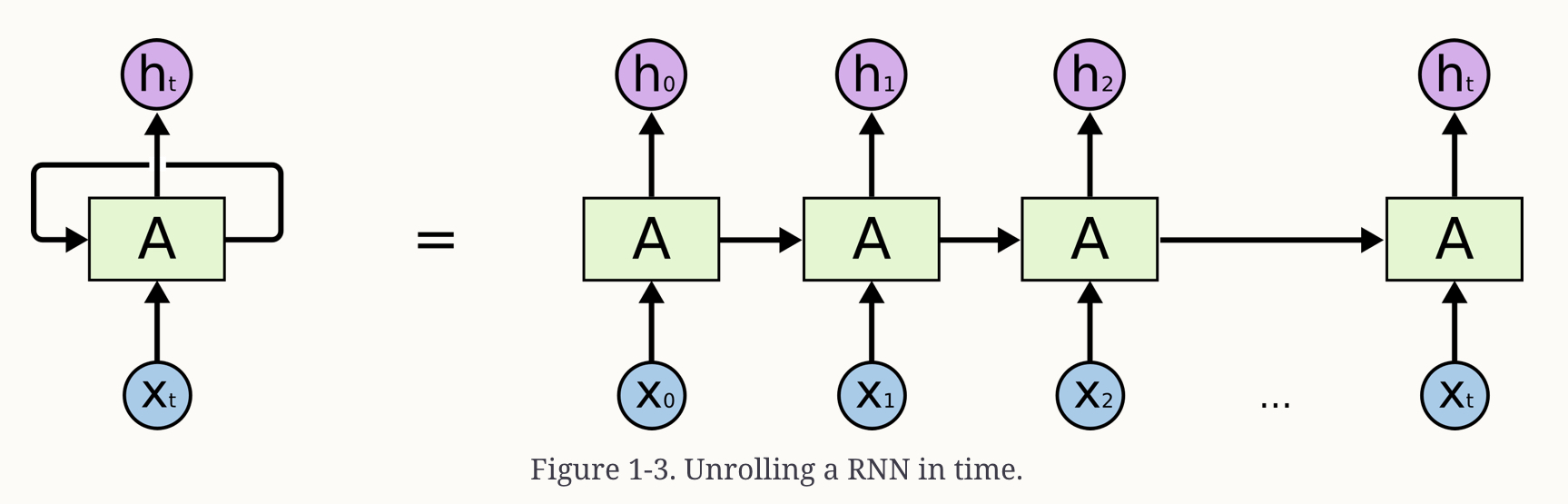
These are still widely used see this blog post on their capabilities.
RNNs played an important role in machine translation, where we want to map one sequence to another. This is usually tackled with an encoder-decoder or sequence-to-sequence architecture, useful where the input and ouput are arbitrary length.
The encoder encodes the information from the input to a numerical representation that is often called the last hidden state. Then the decoder receives that state and generates the output sequence.
The encoder and decoder can be any kind of neural network architecture suited for modeling sequences.
This architecture is elegantly simple, but suffers from an information bottleneck. All the decoder has access to when generating its output is the final hidden state of the encoder. So that final state has to capture the whole meaning of the sequence. This is especially challenging for long sequences where information at the start might be lost in the process of creating a single, fixed representation.
The way out of the bottleneck is to allow the decoder to access all of the encoder’s hidden states. This is done through a mechanism called attention and is key in many modern NN architectures. For more on attention see this paper.
Attention Mechanisms
The main idea is that instead of producing a single hidden state for the input sequence, the encoder outputs a hidden state at each step which the decoder can access.
Some mechanism is needed to prioritize which states to use, using all states at the same time would be too big an input. This is where attention comes in, it lets the decoder assign a weight, or ‘pay attention to’ the specific states in the past which are most relevant for producing the next element (context length can be up to several thousand words for recent models).
This attention process is differentiable, so the process can be learned during training.
Transformer architectures took this a step further and replaced the recurrent units inside the encoder and decoder entirely with self-attention layers and feed-forward networks.
All the tokens are fed in parallel through the model and the self-attention mechanism operates on all states of the same layer. Moving from sequential to parallel processing unlocks huge performance gains, allowing training on much larger corpora.
This self-attention mechanism creates a representation for each token that is dependent on its surrounding tokens. Each token is context aware, so the representation of ‘apple’ (fruit) is different from ‘apple’ (company).
This allowed models to scale, but in many tasks in NLP we don’t have such huge corpora to work with and benefit from the scaling laws in deep learning. This is where the final part came in, transfer learning.
Transfer Learning
Transfer learning is very common in computer vision. You train a CNN on one task and then adapt or fine tune it on a new task. Architecturally, you split the model in terms of a head and body, where the head is the task-specific network.
During pretraining the weights of the body learn broad features of the source domain, and these weights are used to initialize the new model for the new task. This approach typically produces high quality models, with more efficient training in downstream tasks, with less labeled data, than traditional approaches.
In 2017/2018 transfer learning was finally cracked for NLP, most notably ULMFiT mentioned above and ELMo.
ULMFiT involves three main steps:
Pretraining. The initial training objective is simple: predict the next word based on the previous words (ie language modeling). No labeled data is necessary and we can use abundantly available text from Wikipedia etc.
Domain adaptation. Once the language model is pretrained on a large-scale corpus we adapt it on the in-domain corpus, by fine-tuning the weights of the language model.
Fine-tuning. Finally the language model is fine-tuned with a layer for the target task, eg classifying sentiment. Fine-tuning takes orders of magnitude less time, compute, and labeled data compared with training a classifier from scratch.
GPT and BERT
GPT and BERT quickly followed the development of the ULMFiT process. GPT used only the transformer decoder and the same language modeling approach from ULMFIT. BERT on the other hand used the encoder part with a special form of language modeling called masked language modeling. The objective being to predict randomly masked tokens in a text.
These models set new benchmarks and initiated the era of transformer models.
For wider use, the development of Hugging Face proved the further catalyst for adoption.
Introduction to Hugging Face
The chapter then goes on to give an introduction to Hugging Face.
Current Limitations of Transformers
The chapter concludes with the following limitations:
Transformer research is English dominated, hard to find pretrained models for many languages
Data hungry - Although transfer learning helps, we still need a lot of labeled data compared to human performance.
Long docuents - It works very well on paragraph level texts, but becomes very expensive with longer texts like whole documents. This is covered in a later chapter.
Black box - The transformers are black boxes to an extent, it is hard or impossible to unravel why a model made a particular prediction. This limits the context of safe use.
Biases - The models show biases present in the data they were trained on, shown to have racial and gender bias.