Jurafsky Martin Chapter 20: Lexicons for Sentiment, Affect, and Connotation
Metadata
Title: Lexicons for Sentiment, Affect, and Connotation
Number: 20
Introduction
The chapter discusses tools for intepreting affective meaning, extending the discussion in Chapter 04: Naive Bayes and Sentiment Classification
How can we define affective meaning? The chapter sets out the influential Scherer taxonomy used in the module too. It comes from Scherer, Psychological Models of Emotion in Brood Neuropsychology of emotion, OUP 2000.
| State | Description | Examples |
|---|---|---|
| Emotion | Relatively brief episode of response to the evaluation of an external or internal event as being of major significance. | angry, sad, joyful, fearful, ashamed, proud, elated, desperate |
| Mood | Diffuse affect state, most pronounced as change in subjective feeling, of low intensity but relatively long duration, often without apparent cause. | cheerful, gloomy, irritable, listless, depressed, buoyant |
| Interpersonal stance | Affective stance taken toward another person in a specific interaction, coloring the interpersonal exchange in that situation | distant, cold, warm, supportive, contemptuous, friendly |
| Attitude | Relatively enduring, affectively colored beliefs, preferences, and pre-dispositions towards objects or persons. | liking, loving, hating, valuing, desiring |
| Personality traits | Emotionally laden, stable personality dispositions and behavior tendencies, typical for a person. | nervous, anxious, reckless, morose, hostile, jealous |
They characterize sentiment analysis as the extraction of attitude, figuring out what people like or dislike from affect-rich texts like reviews or tweets.
Other states can be extracted too, emotion or moods might be the target if analysing student interactions with a tutorial system or customers with a call center. Emotions like fear might be the target if analysing fiction. Interpersonal stances might be the target if analysing conversations. Can we detect stances like friendliness or awkwardness?
Affect is also important to text generation and creating believable agents.
Chapter 04 focused on Bayesian models, here we focus on another technique where we don’t use every word as a feature, but focus on certain words that carry strong cues to the sentiment. These lists of words are affective lexicons or sentiment lexicons.
Such lexicons presuppose a semantics in which words have affective meanings or connotations (here using connotation in the sense of the aspect of a word’s menaing that is related to the writer or reader’s emotion, opinion or evaluation).
Models of Emotion
Computational models of emotion in NLP have mainly been based on two families of theories of emotion.
Atomic Models
In one family, emotions are viewed as fixed atomic units, limited in number, and from which others are generated, often called basic emotions.
Ekman is maybe the best known of these, presenting 6 basic emotions present in all cultures: surprise, happiness, anger, fear, disgust, sadness. See Ekman, Basic emotions in Dalgleish and Power eds Handbook of Cognition and Emotion Wiley, 1999.
Another is Plutchik’s wheel of emotion, with 8 basic emotions in 4 opposing pairs: joy-sadness, anger-fear, trust-disgust, anticipation-surprise:
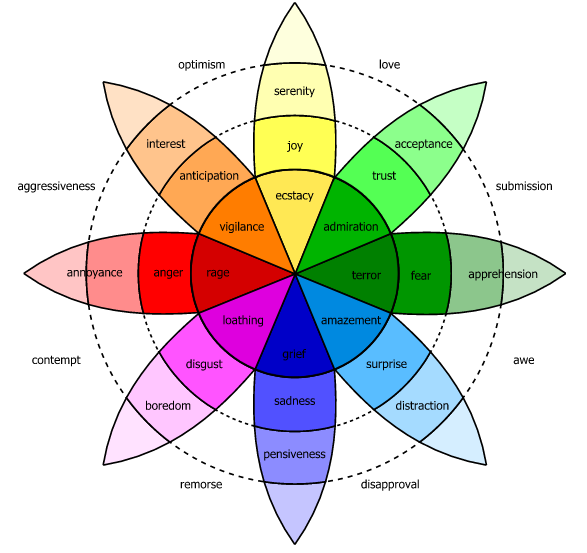
Spatial Models
The second class of emotion theories used in NLP views emotion as a space in 2 or 3 dimensions:
valence: The pleasantness of the stimulus.
arousal: The intensity of the emotion provoked by the stimulus.
dominance: The degree of control exerted by the stimulus.
Most models in this family include valence and arousal, many add dominance as a third dimension.
In sentiment analysis the valence dimension is often used directly as a measure of sentiment.
NLP models are typically more constrained than the richest models in affective science. NLP lexicons typically treat the affective meaning of a word as fixed, irrespective of the context, dialect, or culture of the speaker. Extending NLP models to incorporate the richness of affective science is an ongoing research focus.
Available Lexicons
A wide variety of lexicons have been developed. In the simplest ones words are labeled along one dimension (the ‘sentiment’ or ‘valence’). This might even be represented in a binary fashion in the most simple lexicons, with a wordlist for positive words and one for negative words.
Examples include the General Inquirer the oldest of these. The MPQA subjectivity lexicon, and the Hu and Liu lexicon which used WordNet.
Other lexicons assign each word a value along all three of the affective dimensions. Eg the NRC Valence, Arousal and Dominance lexicon; or EmoLex, the NRC word-emotion association lexicon which uses the Plutchik wheel.
LIWC, the Linguistic Inquiry and Word Count collection consists of 73 lexicons with aspects of lexical meaning for categories like anger, sadness etc.
Creating Lexicons
The earliest method for creating lexicons, still used, is human labeling, perhaps by crowdsourcing. The chapter outlines some of the methods involved in labeling lexicons mentioned above.
Another method is to start with a set of seed words that define two poles of a semantic axis (like good/bad), and then find ways to label each word w by its similarity to the two sets. These are seed-based semi-supervised lexicon induction algorithms.
Semantic Axis Methods
One method originates in Turney and Littman, Measuring Praise and criticism: Inference of semantic orientation from association, 2003. Extended in An et al ->.
First we choose seed words by hand. The affect of a word is different in different contexts. We can deal with this either by choosing a large seed lexicon and rely on the induction algorithm to fine-tune it to the domain; or by choosing different seed words for different genres. The chapter links to some studies of effectiveness of these approaches.
Second, we compute embeddings for each of the pole words. These could be corpus specific (trained from scratch, or fine-tuned) or off-the-shelf.
Once we have the embeddings for each pole word, we compute the centroid vector of those embeddings (this is the multidimensional mean).
Then the semantic axis defined by the poles is the subtraction of the two centroid vectors. (so eg the positive minus the negative centroid vectors). For example:
\[\mathbf{V}_{axis} = \mathbf{V}^+ - \mathbf{V}^-\]
The resulting semantic axis is a vector in the direction of positive sentiment.
Now we can compute via cosine similarity the angle between the vector in the direction of positive sentiment and the direction of w‘s embedding. A higher cosine means that w is more aligned with the set of embeddings associated with positivity.
Label Propagation
An alternative set of methods defines lexicons by propagating sentiment labels on graphs. See the chapter for some relevant papers. One representative algorithm is SentProp from Hamilton et al
First we define a graph. Given word embeddings, we build a weighted lexical graph connecting each word with its k nearest neighbours by cosine similarity. The edges are weighted (see the chapter for the edge weight formula).
Second, we define a seed set where we choose positive and negative seed words.
Third we perform a random walk on the graph starting with the seed set. We choose a node to move to with probability proportional to the edge probability. A word’s polarity score is proportional to the probability of a random walk from the seed set landing on the word.
We walk from both positive and negative seed sets and get a positive and negative raw label score. We combine these values into a positive polarity score.
We can also get a confidence measure by computing the propagation B times over random subsets of the positive and negative seed sets. Then the standard deviation of the bootstrap sampled probability is a confidence measure.
Other techniques
Other techniques are used to measure similarity. Eg conjunction by ‘and’ suggests similar polarity, ‘but’ opposite polarity. Same with morphological negation (un,/im/,/less/), which suggests opposite polarity.
Another technique is to apply polarity to a WordNet synset, rather than an individual word.
Supervised Learning of Polarity and Word Distribution by Category
Another method for sentiment analysis is supervised learning based. We take a corpus of, eg reviews with a score attached and use the score as a label. Positive words are more likely to appear in a 5 star review, negative in a 1 star review.
This lets us assign a word a more complex representation of polarity - a distribution over scores - rather than a binary metric. So in a 5-star system each word could be a 5-tuple with each number a raw count, probability, or some other function from count to score for that class.
The chapter introduces a specific metric and some visualizations of polarity with work from Potts ->
Log Odds Ratio Informative Dirichlet Prior
One very common task is to distinguish words that are more likely to be used in one category of texts than in another. For example, words associated with 1 star reviews versus those with 5 stars. Or words associated with right wing media or politicians and those associated with left wing media or politicians.
A simple method would be to just count frequencies across the classes and look at their difference. Perhaps raw difference or the frequency ratio, or the log odds ratio (the log of the ratio between the odds of the two words). Then we could just sort by whatever measure we chose.
But this doesn’t work well for rare words or very frequent words. There is a solution to this problem, the “log odds ratio informative Dirichlet prior”. It is very useful for finding words that are statistically overrepresented in one category of texts compared with another. It’s based on using another large corpus to get a base prior estimate of what we expect the frequency to be.
Let’s start with the goal. We want to know whether the word w occurs more in corpus i or corpus j. We could just compute the log likelihood ratio:
\[llr(w) = \log \frac{P^i(w)}{P^j(w)}\]
\[= \log p^i(w) - \log P^j(w)\]
\[= \log \frac{f^i(w)}{n^i} - \log \frac{f^j(w)}{n^j}\]
Instead in this method we start with the log odds ratio:
\[lor(w) = \log \left( \frac{P^i(w)}{1-P^i(w)} \right) - \log \left( \frac{P^j(w)}{1-P^j(w)} \right)\]
\[= \log \left( \frac{\frac{f^i(w)}{n^i}}{1-\frac{f^i(w)}{n^i}} \right) - \log \left( \frac{\frac{f^j(w)}{n^j}}{1-\frac{f^j(w)}{n^j}} \right)\]
\[= \log \left( \frac{f^i(w)}{n^i -f^i(w)} \right) - \log \left( \frac{f^j(w)}{n^j - f^j(w)} \right)\]
We then use the dirichlet prior as an estimate of what we expect the frequency of every word to be. We do this by adding the counts from that corpus to the numerator and denominator, so we shrink counts toward the prior. The chapter gives the final statistic mathematically (p. 14).
The chapter also shows the results of the method in a project to extract the characteristic words of very positive or negative restaurant reviews.
Using Lexicons
Having surveyed lexicons and how to create them, the chapter turns to Sentiment Recognition using Lexicons
Connotation Frames
Finally the chapter presents a richer kind of lexicon, known as a connotation frame, that combines affective lexicons with frame semantic lexicons (presented in chapter 10).
The basic insight here is that a predicate like a verb expresses connotations about the verb’s arguments. Take the example of “the UK violated the sovereignty of France”. By using the verb violate the author is expressing sympathy with France and antagonism to the UK. By contrast saying “she survived the event” we express sympathy with the subject of the verb, and negative associations with the event.
These aspects of connotation are inherent to the verb meanings.
Connotation frames can mark other aspects of the predicate towards the argument, including power differentials (“I implore you to reconsider” expresses a differential between I and you), value, effect, mental state, agency.
Connotation frames can be built by hand, or learned by supervised learning.
Some papers to look at for more include Rashkin et al -> and Sap et al ->.