Chollet: Chapter 11: Deep Learning for Text
Metadata
Title: Deep Learning for Text
Number: 11
Core Ideas
There are two kinds of NLP models: bag-of-words models, that process sets of words or n-grams without taking into account their order, and sequence models, that process word order. A bag-of-words model is made of Dense layers, while a sequence model could be a RNN, a 1D convnet, or a Transformer.
When it comes to text classification, the ratio between the number of samples in your training data and the mean number of words per sample can help you determine whether you should use a bag-of-words model or a sequence model.
Word embeddings are vector spaces where semantic relationships between words are modeled as distance relationships between vectors that represent those words.
Sequence-to-sequence learning is a generic, powerful learning framework that can be applied to solve many NLP problems, including machine translation. A sequence-to-sequence model is made of an encoder, which processes a source sequence, and a decoder, which tries to predict future tokens in target sequence by looking at past tokens, with the help of the encoder-processed source sequence.
Neural attention is a way to create context-aware word representations. It’s the basis for the Transformer architecture.
The Transformer architecture, which consists of a
TransformerEncoderand aTransformerDecoder, yields excellent results on sequence-to-sequence tasks. The first half, theTransformerEncoder, can also be used for text classification, or any sort of single-input NLP task.
Introduction and History
In CS we distinguish “natural” languages from languages that were designed for machines. Every machine language was designed, the rules came before use. Natural languages are the opposite. Natural language is messy, ambiguous, chaotic, sprawling, and constantly changing.
The early days of NLP were an attempt to write down the ‘rules’ of natural languages. But natural language is rebellious and resists formalization in this way. The capabilities of such systems remained disappointing after decades of work.
From the late 80s we saw engineers apply ML techniques to corpora to try to get machines to learn the rules themselves. Starting with decision trees, then statistical approaches like logistic regression. Over time learned parametric models took over and linguistics started to be seen by some as a hindrance, not a help.
Most modern NLP does not try to ‘understand’ language as a human does, but ingest a piece of language as input and return something useful, like predicting the topic, sentiment, the next word, the same piece in another language, a summary etc.
So the techniques here look for statistical regularities in the input data, which is sufficient to perform well on many tasks. NLP is pattern recognition applied to words, sentences, and paragraphs.
Much work through the 90s to 2010s was on feature engineering using decision trees and logistic regression. Then from 2015 to 2017 Recurrent Neural Networks started to dominate, particularly bidirectional LSTM models.
Finally around 2017/18 a new architecture rose to replace RNNs, the Transformer. Most NLP systems now are based on Transformers.
Pre-processing
The chapter first walks through Preprocessing Text in keras. It is familiar material from cm3060 Natural Language Processing but includes some pointers on using the keras utilities.
Representing Groups of Words
The chapter then walks through Word Order Models, reviewing bag-of-words models, sequence models, and word embeddings.
The Transformer Architecture
Next the chapter takes us through the Transformer Architecture.
Choosing Between Sequence Models and Bag-of-words
Chollet’s research suggests the following approach to choosing whether to go with sequence models and bag-of-words approaches.
The key factor is the ratio between the number of samples in your training data and the mean number of words per sample. If the ratio is > 1500 go with a sequence model. Otherwise, bag of words:
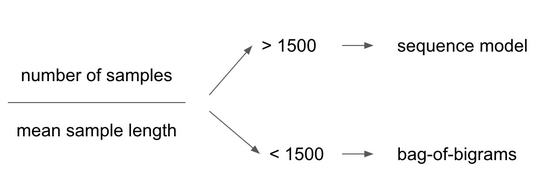
This intuitively makes sense: the input of a sequence model is a richer, more complex space, so it takes more data to map the space. Meanwhile, a plain set of terms you can train logistic regression on top using a few hundred or thousands of samples.
The shorter an example is the less a model can discard information. In particular, word order becomes important. With a longer sample, word statistics would become more reliable and the topic or sentiment would be clearer from the word histogram alone.
This is just a rule of thumb, and only for classification. For other tasks like translation, sequence models come into their own.
Sequence to Sequence Learning
So far we’ve just looked at classification, but there is more to NLP than that. The chapter turns to Sequence to Sequence Learning