Preprocessing Text in keras
As presented in Chollet: Chapter 11: Deep Learning for Text
Since deep learning models are differentiable functions, they need to operate on numeric tensors. Vectorizing text is the process of transforming raw text into numeric tensors. There are many approaches but they all follow a standard template:
standardize the text to make it easier to process, eg convert it to lower case or remove punctuation.
tokenize the text, split it into tokens such as characters, words, or groups of words.
Index the tokens present in the data and convert each token into a numerical vector.
It looks like this:
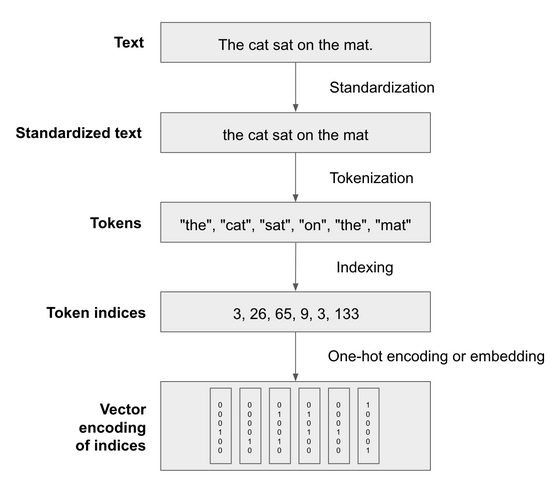
Standardization
Text standardization is a basic form of feature engineering that aims to erase encoding differences that you don’t want your model to have to deal with. Consider the following:
“sunset came. i was staring at the Mexico sky. Isnt nature splendid??”
“Sunset came; I stared at the México sky. Isn’t nature splendid?”
We parse these as near identical in meaning, but their byte string representations would look very different. Some steps we could take to bring them closer together include:
convert to lowercase and remove punctuation.
replace special characters like accents with some standard form.
Stemming or lemmatization (this is rarely used in ML though, more in IR).
Following these steps will mean your model needs less training data and will generalize better. But the right steps are task dependent. You don’t want to remove ‘?’ characters in QA tasks for example.
Tokenization
After standardization you need to break your text up into units to be vectorized, ie tokens. You could do:
Word-level tokenization or its variant sub-word tokenization. Here tokens are space or punctuation separated substrings. In sub-word tokenization we might treat “staring” as “star+ing” or “star” “ing”.
N-gram tokenization where tokens are groups of N consecutive words.
Character tokenization this is rarely used, only for specialized tasks like text generation and speech recognition.
As a rule of thumb, if you are building a sequence model use word/sub-word tokenization. If you are building a bag of words model, use N-grams.
The effect of N-grams is to inject a large amount of local word order information into the model, hence they’re useful for bag of words models which otherwise throw that all out.
Vocabulary Indexing
Once you have your tokens, you need to convert them to a numeric value.
You could do this in a stateless way, by hashing them. But in practice the way you do it is to build an index of all terms found in the training data (the vocabulary), and assign a unique integer id to each entry in that vocabulary.
Naively it would look like this:
vocabulary = {}
for text in dataset:
text = standardize(text)
tokens = tokenize(text)
for token in tokens:
if token not in vocabulary:
vocabulary[token] = len(vocabulary)
def one_hot_encode_token(token):
vector = np.zeros((len(vocabulary), ))
token_index = vocabulary[token]
vector[token_index] = 1
return vector
Any text dataset will feature an extremely large number of tokens, most of which only show up once or twice. Indexing those would create a huge feature space where most features don’t convey much information at all. So we tend to restrict the vocabulary to the top 20,000 or 30,000 most common tokens or so.
There are two special tokens to be aware of that are widely used:
Index 0 is given to a mask token which means “ignore me, I’m not a word”. This is used for padding, since input sequences to a model often need to be the same length, and text is variable length. If you want to feed the sequence [8, 32, 12] into a model that expects 5 tokens, you would pad it to [8, 32, 12, 0, 0]
Index 1 is given to an OOV index meaning out of vocabulary. This covers tokens seen in test data but not in the training data (or not kept in the vocab). This enables us to do token_index = vocabulary.get(token, 1) and avoid key value errors for tokens not in the vocab. It’s often represented as [UNK].
(Other special tokens not mentioned yet are sequence separator and classifier tokens, these can vary by model)
Keras TextVectorization Layer
Although you can write all this in Python easily enough, performance can be fiddly. So Keras offers a TextVectorization layer which is fast and can be dropped into a tf.data pipeline or Keras model.
You can see the details in the docs
By default it uses ‘convert to lowercase and remove punctuation’ for standardization and ‘split on whitespace’ for tokenization. But you can pass custom functions for both, which should operate on tf.string tensors, not Python strings. See more on tf.strings
To index the vocabulary of a corpus, you call adapt on the layer with a Dataset object that yields strings, or just with a list of Python strings: text_vectorization.adapt(dataset)
Then to retreive the compound vocabulary, sorted by frequency, you call text_vectorization.get_vocabulary() - this means you can turn your vectors back into their original text tokens.
Here’s an example of the round trip:
vocabulary = text_vectorization.get_vocabulary()
test_sentence = "I write, rewrite, and still rewrite again"
encoded_sentence = text_vectorization(test_sentence)
print(encoded_sentence)
# tf.Tensor([ 7 3 5 9 1 5 10], shape=(7,), dtype=int64)
inverse_vocab = dict(enumerate(vocabulary))
decoded_sentence = " ".join(inverse_vocab[int(i)] for i in encoded_sentence)
print(decoded_sentence)
# "i write rewrite and [UNK] rewrite again"
For implementation, during training you’ll want to use the TextVectorization layer in a tf.data pipeline, not in the model itself. This is because it runs on the CPU, and if you have it in the model, all the subsequent layers will have to wait for the preprocessing to finish before they do their work on the GPU. If you put it in the pipeline you can do the preprocessing asynchronously.
For deployment, you’ll likely want to flip that and put the TextVectorization layer in the inference model itself. Otherwise you’re going to have to do that pre-processing somewhere else, and that could introduce discrepencies in how it’s done.
To do that you just create a new model that uses the layer, and adds it to the model you built in training. The resulting model can process batches of raw strings:
inputs = keras.Input(shape=(1,), dtype="string")
processed_inputs = text_vectorization(inputs)
outputs = model(processed_inputs)
inference_model = keras.Model(inputs, outputs)
# now we can accept raw strings:
raw_text_data = tf.convert_to_tensor([
["That was an excellent movie, I loved it."],
])
predictions = inference_model(raw_text_data)
print(f"{float(predictions[0] * 100):.2f} percent positive")