Sequence-to-sequence Models (Chollet)
As discussed in Chollet: Chapter 11: Deep Learning for Text
A sequence-to-sequence model takes a sequence as input (typically a sentence or paragraph) and translates it into a different sequence. This is at the heart of many applications of NLP: Machine translation; text summarization; question answering; chatbots; text generation etc.
The general template in seq-to-seq models is shown in the diagram below:
In the training stage:
An encoder turns the source sequence into an intermediate representation.
A decoder is trained to predict the next token
iin the target sequence by looking at both previous tokens (0toi - 1) and the encoded source sequence.In the inference stage we don’t have the target sequence, we generate it one token at a time:
The encoded source is obtained from the encoder.
The decoder starts by looking at the encoded source sequence and the initial ‘seed’ token (like
[start]) and predicts the first token in the sequence.The predicted sequence so far is fed back into the decoder, which generates the next token and so on, until it generates a stop token (like
[end]).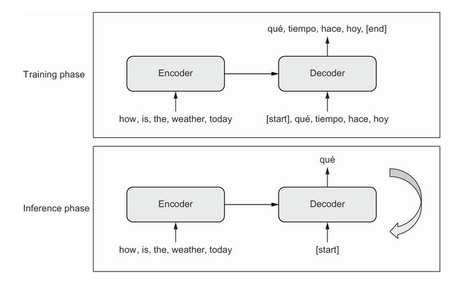
pp. 351-4 walk through preparing a sample dataset for a machine translation task.
Sequence-to-sequence with RNNs
Before transformers came along, seq-to-seq learning was done with stacks of RNNs. It’s still worth knowing about this approach.
The naive way to use RNNs to turn a sequence into another would be to just keep the output of the RNN at each time step, like this:
inputs = keras.Input(shape=(sequence_length,), dtype="int64")
x = layers.Embedding(input_dim=vocab_size, output_dim=128)(inputs)
x = layers.LSTM(32, return_sequences=True)(x)
outputs = layers.Dense(vocab_size, activation="softmax")(x)
model = keras.Model(inputs, outputs)
But in practice we can’t do it that way. Due to the step-by-step nature of RNNs, the model will only be looking at tokens 0..N when predicting token N in the target. This just doesn’t work for translation.
Instead we need to parse the whole of the input, and then use that as an initial state in generating the output sequence. This is what the encoder/decoder structure accomplishes. The state could be the last output of the encoder RNN, or its final internal state vectors.
The decoder will look at this initial state, along with tokens 0..N in the target sequence to predict token N+1.
Here’s how you’d implement the encoder and decoder:
from tensorflow import keras
from tensorflow.keras import layers
embed_dim = 256
latent_dim = 1024
# the encoder
source = keras.Input(shape=(None,), dtype="int64", name="english")
x = layers.Embedding(vocab_size, embed_dim, mask_zero=True)(source)
encoded_source = layers.Bidirectional(
layers.GRU(latent_dim), merge_mode="sum")(x)
# the decoder
past_target = keras.Input(shape=(None,), dtype="int64", name="spanish")
x = layers.Embedding(vocab_size, embed_dim, mask_zero=True)(past_target)
decoder_gru = layers.GRU(latent_dim, return_sequences=True)
x = decoder_gru(x, initial_state=encoded_source)
x = layers.Dropout(0.5)(x)
target_next_step = layers.Dense(vocab_size, activation="softmax")(x)
seq2seq_rnn = keras.Model([source, past_target], target_next_step)
seq2seq_rnn.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
seq2seq_rnn.fit(train_ds, epochs=15, validation_data=val_ds)
You’ll likely use BLEU scores to evaluate translation models.
RNN approaches have a few fundamental limitations. The source sequence representation has to be held entirely in the encoder state vector(s), which puts limitations on the size and complexity of the sentences you can translate. It’s like translating a sentence entirely from memory, without looking twice at the source sentence when producing the translation.
Also RNNs struggle with long sequences as they tend to forget about the distant past. By the time you reach the 100th token, little info remains about the first. Long term context is forgotten, which is an issue in translating long documents.
Sequence-to-sequence with Transformers
Transformers are designed to overcome these limitations of RNNs for seq-to-seq tasks.
Intuitively, if you were translating a document you would probably want ot go back and forth between the source sentence and your translation in progress, paying attention to different bits of the source as you go along. This is what Transformer models enable.
Remember that the Transformer encoder uses self-attention to produce context-aware representations of each token in the input. It keeps the encoded representation in a sequence format, it’s a sequence of context-aware embedding vectors.
The second half of the model is the Transformer decoder. Just like the RNN decoder it reads tokens 0..N in the target sequence to predict N+1. But while it does so it uses neural attention to identify which tokens in the encoded source are most closely related to the target token it’s currently trying to predict.
In the query-key-value model the target sequence serves as an attention “query” that is used to pay closer attention to different parts of the source sequence. The source sequence itself is the key and value.
Here’s what the decoder looks like:
There’s a self-attention block that looks at the current target (0..N), then there’s another attention block that looks at the encoded source each time. Finally there are the usual normalization and dense layers that yield a softmax prediction.
There’s one issue to be aware of causal padding. The decoder has access to the whole target sequence during training. Left to itself it could just read the next token and copy it to the location N in the output.
The fix is straightforward, we add a causal attention mask to prevent the model paying attention to information from the future.
Here then is the full Transformer Decoder class (see p. 359ff for more detail):
class TransformerDecoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim
self.dense_dim = dense_dim
self.num_heads = num_heads
self.attention_1 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.attention_2 = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
self.layernorm_3 = layers.LayerNormalization()
self.supports_masking = True
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config
def get_causal_attention_mask(self, inputs):
input_shape = tf.shape(inputs)
batch_size, sequence_length = input_shape[0], input_shape[1]
i = tf.range(sequence_length)[:, tf.newaxis]
j = tf.range(sequence_length)
mask = tf.cast(i >= j, dtype="int32")
mask = tf.reshape(mask, (1, input_shape[1], input_shape[1]))
mult = tf.concat(
[tf.expand_dims(batch_size, -1),
tf.constant([1, 1], dtype=tf.int32)], axis=0)
return tf.tile(mask, mult)
def call(self, inputs, encoder_outputs, mask=None):
causal_mask = self.get_causal_attention_mask(inputs)
if mask is not None:
padding_mask = tf.cast(
mask[:, tf.newaxis, :], dtype="int32")
padding_mask = tf.minimum(padding_mask, causal_mask)
attention_output_1 = self.attention_1(
query=inputs,
value=inputs,
key=inputs,
attention_mask=causal_mask)
attention_output_1 = self.layernorm_1(inputs + attention_output_1)
attention_output_2 = self.attention_2(
query=attention_output_1,
value=encoder_outputs,
key=encoder_outputs,
attention_mask=padding_mask,
)
attention_output_2 = self.layernorm_2(
attention_output_1 + attention_output_2)
proj_output = self.dense_proj(attention_output_2)
return self.layernorm_3(attention_output_2 + proj_output)
The actual model we train, then, is a combination of all the pieces looked at so far, positional embeddings, an encoder, and a decoder:
embed_dim = 256
dense_dim = 2048
num_heads = 8
encoder_inputs = keras.Input(shape=(None,), dtype="int64", name="english")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(encoder_inputs)
encoder_outputs = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
decoder_inputs = keras.Input(shape=(None,), dtype="int64", name="spanish")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(decoder_inputs)
x = TransformerDecoder(embed_dim, dense_dim, num_heads)(x, encoder_outputs)
x = layers.Dropout(0.5)(x)
decoder_outputs = layers.Dense(vocab_size, activation="softmax")(x)
transformer = keras.Model([encoder_inputs, decoder_inputs], decoder_outputs)
transformer.compile(
optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
transformer.fit(train_ds, epochs=30, validation_data=val_ds)