cm3020 Lecture Summaries: Topic 04
Lectures from the generative systems case study in cm3020 Artificial Intelligence
Week One: Introduction
16.103: Generative Systems
Introduces the idea of generative systems.
Distinguishes between passive tools (like a paintbrush) and active tools.
Defines a passive tool as one that is not capable of acting independently.
Shows some ‘active tools’ - Google Magenta’s sketch RNN, and OpenAI’s DALL.E text-to-image. Also shows Conway’s Game of Life.
Introduces the Boden and Edmonds taxonomy in Boden and Edmonds: What is Generative Art?
Introduces the paper by Tatar and Pasquier: Musical Agents, discussing the different ways of breaking down a generative system and describing its features.
16.105: Worked Example
Demonstrates a simple generative system using Markov models.
Presents Markov language models. For more detail see N-Grams (Jurafsky Martin), Manning Schutze: Chapter 06: Statistical Inference, and generally cm3060 Topic 03: Language Modelling.
In terms of generative systems we think of language modelling this way:
First pick a random state (word) from observed states
Next select at random from possible next states. Repeat while possible states available.
If no possible next state, return to first step.
Introduces second-order models (bigrams). Variable order markov models are still used.
More complex models differ from this simple basis by having a more comples model of the sequence than a transition table. They have a more complex method for picking the next state, including more complex state.
Examples of more complex models include LSTM networks, and transformer models.
16.107: Markovian Text Generator
Codes a Markov model:
from collections import defaultdict
input = "once upon a time I watched a man live code a Markov model"
words = input.split()
model = defaultdict(lambda: [])
for i, w in enumerate(words):
if i < (len(words) - 1):
model[w].append(words[i+1])
Then sampling:
import random
state = random.choice(list(model.keys()))
output = state
for i in range(10):
state = (random.choice(model[state])
if model[state]
else random.choice(list(model.keys())))
output = output + " " + state
Week Two: Text Generation
17.103: What is a Transformer?
Introduces the Transformer Architecture as being able to take account of both sequence and context.
Introduces the topic of Word Order Models distinguishing bag of word models from sequence models.
Introduces the self-attention mechanism and how the transformer architecture builds on it. Points to Chollet for more. The explanation in the lecture is not very clear or helpful.
17.105: GPT-2
Introduces the GPT-2 model and demos hugging face.
Talks about the Open AI decision not to release it at the time due to concerns about fake news etc.
Describes the model - uses self-attention with multiple heads to generate multiple projections. Can operate in auto-regressive mode, to generate endless streams of words.
Its big contribution in the paper was zero-shot learning, performance on tasks with no fine-tuning.
Introduces Hugging Face and does a very quick demo on using the pretrained model to generate text. Shows the model - 770 million parameters! and the process for downloading and running a pretrained model from hugging face.
Explains why we’re not using GPT-3 - too great hardware constraints. Can only access via cloud API, and have to pay. GPT-2 is good enough for the task here.
17.107 Fine-Tuning GPT-2
Largely practical lecture walking through the fine-tuning process. Distinguishes conditioning - feeding an input into an existing network to determine the text generated - from fine-tuning which involves fine-tuning weights on a small, new dataset.
Walks through collecting the song lyrics from kaggle, in JSON form, and extracting a clean csv. Trained it on an Nvidia 2070 with a batch size of 2.
Shows the run_clm.py script which appears to be this one.
Shows some code for loading the fine tuned model:
from transformers import TFGPT2LMHeadModel
from transformers import pipeline
model = TFGPT2LMHeadModel.from_pretrained('./')
generator = pipeline('text-generation', model=model, tokenizer='distilgpt2')
Week Three: Music Generation
18.103: History of Automated Music Composition
Gives a potted history of computationally aided composition.
Starts by giving a quote saying that the problem of computer-aided composition is not well defined. Gives some examples of early non-computer examples of stochastic or algorithmic composition.
Then gives some computational examples:
1950s: Hiller’s expermients with the Illiac Suite - random selection, filtering by testing against rules, randomly generated markov chains.
1950s: The Music I langauge, Max Mathews.
Moves through the 60s and 70s, refers to Cage and Koenig, Lauren Spiegel, Xenakis.
80s introduced more complex techniques, introduced expert systems to composition, eg in creating harmonization.
90s introduces genetic algorithms, L-systems - bio-inspired stuff.
2000s introduces machine listening, George Lewis, start of proper collaboration, agent listens and responds.
2010s OpenAI Jukebox, can generate raw audio, trained on millions of songs. Deep learning in full force.
18.105: Introduction to Latent Spaces
Discusses the representation of music, the problem with rule-based approaches, and then the idea of a statistical latent space. For more on this see Chollet: Chapter 12: Generative Deep Learning
We might represent music with a hand-crafted grammar, but the grammar rules swiftly become very complicated.
Deep learning techniques can make creation feasible when the desired application is too complex to be described by analytical formulations or manual brute force design. (Fiebrink and Caramiaux, The ML algorithm as creative musical tool, 2016, arxiv).
DL allows us to build models that learn the statistical structure of the dataset. Latent spaces are a way of thinking about the learned statistical structure.
Latent spaces are:
a compact way of describing a dataset.
The output of a learned, reversible dimension reduction technique
Ideally, the latent vector captures the pertinent characteristics of a given datapoint and disentangles factors of variation in a dataset (Roberts et al, citation obscured by MYK’s head).
The latent spaces we will use are learned, reversible, and explorable. It could be the space of all possible songs, or the space of all possible sounds.
We’re going to look at the Music-VAE latent space, it takes in a 2 or 16 bar musical sequence (pitches, duration, timing). The sequence can have multiple parts, eg 1 (melody), 3 (bass, melody, drums) or more. It encodes to a 256 or 512 D latent vector.
So the process is we get a set of examples of the thing (eg a set of classical music, or pop music); then learn a lower dimensional representation of the elements in the set (the latent space). Then we can generate a vector in the latent space and translate back from the low-D space to the higher dimensional one.
18.107: What is Music-VAE?
Introduces the Music-VAE from Google Magenta, which is:
a recurrent, hierarchical, variational autoencoder model for the encoding and decoding of musical note sequences. (Roberts et al 2018)
An autoencoder is a neural network that learns a latent space. It can encode to that space, and decode from it.
Why variational? Close points in autoencoder space might not be close when decoded. So it is not useful for generative exploration. Variational autoencoders try to solve this. Draws an analogy with word embeddings.
AEs encode to a vector, but VAEs encode to the parameters of a statistical distribution - mean and variance.
Why recurrent? It’s a bidirectional LSTM - we send in a sequence of notes.
The decoder is a hierarchical LSTM, which ensures better use of the latent representation.
Trained on 1.5 million MIDI files. Extracted 16 bar long sections with a sliding window. Quantized to 256 steps in 16 bars.
18.109: JavaScript Promises
Crash course in Async JS and promises.
We use JS as it’s easy to install, but at the moment the python package wasn’t easy to get running.
Really bad explanation of promises, best to skip it.
18.111: Working with MusicVAE
MusicVAE expects a client-server interface. You can serve the model from a local webserver. The model is instantiated asynchronously, so you can chain callbacks to do stuff with the sample.
The lecture is a practical walkthrough of getting it all up and running.
18.113: Rendering Audio with MusicVAE and fluidsynth
Midi is a standard protocol for digital musical instruments. General midi is a standard for synthesizer specifications. It’s also a file format.
Walks through outputting midi from the model. Uses Reaper to visualize the midi file.
Introduces sound fonts. FluidSynth is software that can render out midi files to wav: https://www.fluidsynth.org/
Shows the end to end process of rendering the audio file to play it.
18.115: Exploring Latent Space
If you sample randomly your samples will come from anywhere in the latent space and you’ll end up with very different arrangements.
You can permute samples instead. We generate a latent vector and store it. Now we can re-use it. We can introduce some variation in the base vector to generate a slightly different musical output.
By permuting vectors slightly as you go, you can generate some variation in the song as you go along.
Week Four: Speech Synthesis
19.103: Speech and Vocal Synthesis
Speech synthesis has long been an area of CS research. Shows the pink trombone app from n. Thapen (2017). It’s a physical model of a vocal tract. But it doesn’t have a language model, so it creates sounds but not words.
Traces a quick history of voice synthesis:
1960s: Matthews, Kelly and Lockbaum at Bell labs: physical model of a tube of moving air. Used in 2001 movie.
1970s: LPC (Speak and Spell)
1980s: phase vocoder
1990s: realtime, variety of techniques, HMM systems
2000s: vocaloid, concatenative spectral synthesis - sticks together chopped up phonemes from real recordings to generate new words based on language models.
2010s: deep models - some move into audio level models.
Challenges of singing over speech include timing, expressiveness, and holding long notes.
DL based systems are appearing rapidly in the late 2010s and early 2020s, examples include XiaoiceSing (2020), HiFiSinger (2020) and Diffsinger (2021).
We’ll be using Diffsinger, but MYK couldn’t get the official one to work, so we’ll be using a different implementation.
19.105: Background for diffsinger
Introduces the terminology and background of the library.
Notes that the field is really challenging and the state of the art is beyond the level you’d expect of an undergrad course. This will be an intuitive explanation.
Describes the process. First he read a bunch of papers. Then he had to find some source code, trying to get the code to run. There were library clashes and other issues.
Defines some terms
embedding - mapping a high demensional space to a more meaningful lower dimensional space.
convolutional - see the game playing case study.
transformers - see the GPT2 week in this case study
signals - a list of numbers that may be 1D, or 2D, representing a signal from the world.
linguistic - models with knowledge of language in them
vocoder - controllable synthesizer with frequency bands.
Describes the key reading, including the diffsinger paper, and the HiFi-GAN paper.
We’ll be using the LJ Speech dataset.
And this implementation of DiffSinger.
19.107: Diffsinger models
Text, pitch, and duration goes in, the wav file comes out.
Within that there are three sub-models, language, speech, and vocoder.
They are broadly connected like this:
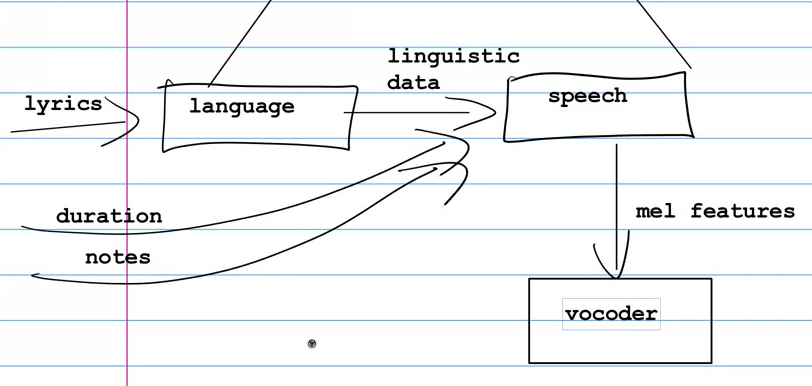
In the language model, the text goes in, and the model converts it into phonemes. It seems to do this through look-up of a hand-crafted map from word to a set of phonemes.
The speech model is multiple models that are stacked up. There’s a text encoder model, a speaker embed for sound data, variance adaptor (applying pitch and other modifications), a diffusion model, probably more. It ends up with hundreds of layers stacked on each other.
Finally the vocoder model takes in the mel features output from the speech model and turns them into an actual sound. It’s essentially lots and lots of convolutions.
19.109: Working with DiffSinger
The basic operation is to install all the packages, then run sing.py with the flags --lyrics, --notes, --dur.
Notes are a comma separated list, duration in seconds.
Walks through the control flow of the execution.
A couple of issues were duration and tuning the singer.
For duration he renders out with a target of 1, sees how long the output is, and then scales accordingly.
First attempts the model would just talk rather than sing. He had to manually adjust the pitch to get the right notes.
Week Five: Pulling it Together
20.103: Extracting Notes
Walks through the steps in generating lyrics, music, and then extracting out the note sequence from the midi file. These are used as input to the voice synthesizer through manual copy-paste.
20.105: Mixing the singing and backing
Shows the mix in Reaper, which is a commerical tool. Then with Audacity, which is open source.
Finally we do it with librosa, which is a python library.
20.109: Creativity
Philosophy time.
Introduces Bloom’s taxonomy, where creativity is at the top of hierarchy of understanding:
What is creativity? “It was at once a psychological power, and a process in the mind, as well as also being the product of that process” (about emergence of word creativity in the 1950s) (Still and d’Iverno, HIstory of creativity).
Skinner: attributes creativity to ‘behavioural mutations’, unusual acts emitted accidentally but selected by the environment for reinforcement.
Dewey: Creativity is at the root of intelligence, rooted in creativity is the concept of creative inquiry. Humans are creative creatures.
Mead: ‘The individual in his experiences is continuously creating a world which becomes real through his discovery.’
Boden: ‘Creativity can be defined as the ability to generate novel, and valuable, ideas.’
Jordanous: ‘Creativity research offers the Four Ps of creativity: Person/Producer, Product, Process and Press/Environment’.
Still and d’Inverno: G-creative, the mind as a closed system, isolated from the world of nature but adding to nature by God-like process of creation. N-creative, treat mind and nature as inseparable parts of an open system.
Can computers be creative? Boden: many people are saying that computers can’t be creative even if their performance might match human examples.