Jurafsky Martin Chapter 13: Constituency Parsing
Metadata
Title: Constitutency Parsing
Number: 13
Core Ideas
Syntactic parsing is the task of assigning a syntactic structure to a sentence.
The output is a parse tree, which are used in applications like grammar checking. They can also be used as intermediary representations in semantic analysis, and so can play a role in applications like question answering.
The main challenge in parsing algorithms is dealing with ambiguity. The chapter discusses this first before presenting the CKY algorithm (Cocke-Kasami-Younger), which is the standard dynamic programming approach to syntactic parsing.
Finally it turns to dealing with how to choose which of the possible parse trees is correct.
Ambiguity
Rehearses the “I shot an elephant in my pyjamas” example of syntactic ambiguity.
Structural ambiguity has many forms. One common form is attachment ambiguity, when a particular constituent can be attached to the parse tree at more than one place, eg the elephant example or gerundive-VPs like “I saw the Eiffel tower flying to Paris”.
Another is coordination ambiguity arising from conjunctions like and. EG “old men and women” - are the women old?
In practice there are often many syntactially valid but semantically unreasonable parses for a complex sentence.
CKY Parsing
Dynamic Programming provides a powerful framework for parsing algorithms that work with context free grammars. Once a constituent is identified we can record its presence and make it available for use in subsequent derivations that need it. Since dynamic programming involves building a table or chart of sub-problem solutions, it is often referred to as chart parsing.
The most frequently used approach is the CKY algorithm. This involves three steps. The book has full details, they are only lightly summarised here. Manning’s lecture explains it well.
Step One: Convert to CNF
The grammar has to be converted to CNF if not already in that form. The book walks through this conversion, which is familiar from the theory module.
The reason is efficiency as Manning explains in the lecture. Without binarization - ie ensuring at most two tokens on the right of each production, the run time becomes higher order polynomial or exponential. With binarization it’s cubic.
Step Two: Recognition
Step two involves building a chart or parse triangle. Imagine half a matrix laid out over our input sentence:
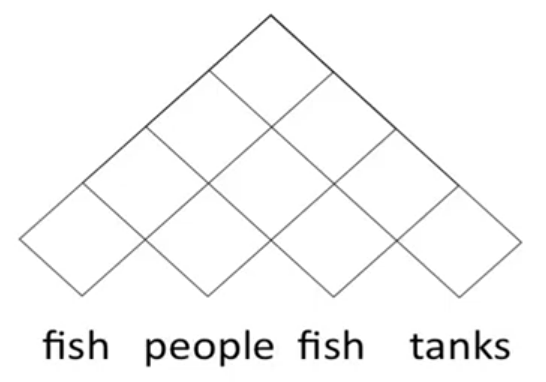
The bottom row of cells will be the constituents that can be formed by the single words (POS tags), the second row up will be those that can be formed by the relevant bigrams (project out the lines in the triangle to see what will be included) and so on, up to the full sentence.
First we fill in the bottom row, then the second, all the up to the top.
How do we fill in the cells? The lecture from Manning shows it more clearly than the book but in a probabilistic framework.
Step Three: Build the Tree
Finally we follow pointers back through the table to build the parse tree.
Span-Based Neural Constituency Parsing
The book then walks through extending the CKY parsing algorithm to use neural language models to resolve ambiguity.
The parser learns to map spans of words to a constituent. It builds up larger and larger spans bottom-up, like the traditional algorithm. But unlike the traditional algorithm it doesn’t do so using hand-written grammar rules, it relies on learned neural representations of spans to encode likely combinations. Page 9 onwards has a detailed walkthrough.
Evaluating Parsers
See also the video lecture from Chris Manning, including some criticism of standard evaluation metrics.
The standard tool is the PARSEVAL metric, which measures how much the constituents in the hypothesis parse tree look like the constituents in a reference, gold-standard parse. So we generally draw on a treebank like Penn for evaluation.
We can then calculate labeled recall (# of correct constitutents in hypothesis/# of correct constituents in reference).
And labeled precision (# of correct constituents in hypothesis/# of total constituents in hypothesis)
And take their F1 as usual (2PR/P+R).
Partial Parsing (Chunking)
Many tasks don’t require a full parse tree. We can use a partial parse or shallow parse for such tasks.
For example, in information extraction we generally don’t extract all information in the text, we identify and classify segments of text that are likely to contain valuable information.
Chunking is a type of partial parsing. We identify and classify flat, non-overlapping segments of a sentence that constitute the basis non-recursive phrases that correspond to the major content-word POS (noun phrases, verb phrases, adjective phrases, and prepositional phrases).
It is particularly common to find all the basic noun phrases in a text.
Chunked text lacks hierarchy, it’s expressed as a flat list of bracketed chunks like “[{NP} The morning flight][{PP} from][{NP} Denver][{VP} has arrived]”
We see from this that chunking involves two fundamental tasks: segmentation (separating non-overlapping extents of chunks) and labeling (annotating the chunk with the correct tag). Some input words may not be part of any chunk (eg in base NP extraction).
Although there is variety, it’s common to say that base phrases/chunks must not contain any constituents of the same type. IE we eliminate recursion.
We include the head of the phrase along with any pre-head material within the constituent, but elminate post-head material.
Chunking is usually done through supervised machine learning.
CCG Parsing
The chapter concludes with CCG parsing algorithms, since they’re beyond the scope of the module I’m not noting them.