Sharma et al: Building a Legal Dialogue System
Metadata
Title: Building a Legal Dialogue System: Development Process, Challenges, and Opportunities
Authors: Sharma, Russell-Rose, Barakat, Matsuo
Publication Year: 2021
Journal: Arxiv preprint
Abstract
This paper presents key principles and solutions to the challenges faced in designing a domain-specific conversational agent for the legal domain. It includes issues of scope, platform, architecture and preparation of input data. It provides functionality in answering user queries and recording user information including contact details and case-related information. It utilises deep learning technology built upon Amazon Web Services (AWS) LEX in combination with AWS Lambda. Due to lack of publicly available data, we identified two methods including crowdsourcing experiments and archived enquiries to develop a number of linguistic resources. This includes a training dataset, set of predetermined responses for the conversational agent, a set of regression test cases and a further conversation test set. We propose a hierarchical bot structure that facilitates multi-level delegation and report model accuracy on the regression test set. Additionally, we highlight features that are added to the bot to improve the conversation flow and overall user experience.
Key Points
The paper outlines a dialogue agent built for the legal sector. It uses a retrieval-based approach and was built on AWS’s Lex service.
Requirements and Approach
The system aims to replicate FAQ - answering general questions related to the services offered by a law firm; and fact finding - identifying the particular service a user needs based on their case description, then recording their contact details and case description.
The dialogue model uses a traditional slot and intent approach. Custom slots defined included practice_type with various legal services as values.
For intents, the FAQ use case intents are defined according to input, examples include Cost, for questions about price, or Prep_app for appointment preparation and documentation.
For Fact Finding, intents are specific to the identified practice_type. They first tried conflating intents like contract drafting across services, but this didn’t work.
Architecture
Bot Hierarchy
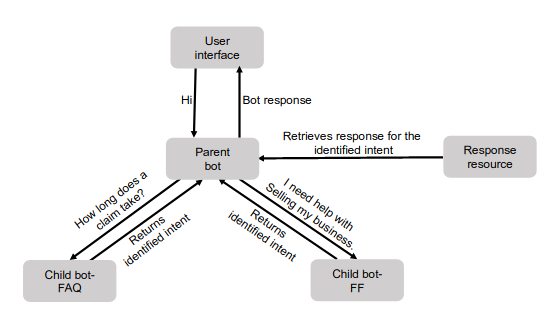
The team had to implement a parent-child hierarchy of bots. This was partly to manage the limits on number of permitted slots and intents in a bot in AWS, also for modularity and ease of maintenance. The user interacts with a parent bot, with 14 intents. It handles basic intents such as greet and goodbye.
The parent bot has two custom intents, all_faq and all_ff which aggregate all the intents of the child bots. Once it matches one of these, it hands off the query to the relevant child bot’s classifier. This child bot specifies the intent and returns it to the parent bot, which then retrieves a response from the response resource.
This structure is extensible, such that the child bots could then have children of their own.
Software Architecture
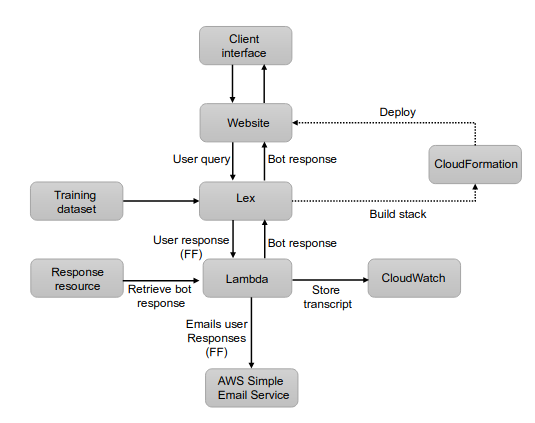
The software architecture was built around AWS services.
Lambda for controling the conversational flow and messaging CloudWatch, which is used for monitoring and logging. Lambada can also trigger the AWS email service to email customer queries for the FF service.
CloudFormation is used to bundle the resources for deployment as a stack.
Data Collection
The team started with 150 baseline utterances assembled with subject matter experts. A baseline model was trained on this set.
They added to this ‘crowdsourced’ utterances, but not really crowdsourcing as they got 4 students to populate utterances based on templates.
The final data source was three years of logs of user enquiries from a web form. The web form included a legal services category in the metadata. This was preserved for classification, along with the message body. Then the text of the body was manually reviewed and relevant sentences stripped out for use as training input.
All the utterances from sources 2 and 3 were reviewed, filtered for relevance, clarity etc, and then manually labelled with corresponding intents. These were run through the baseline model and a portion of correctly labeled examples were reserved as a regression test set.
They ended up with a modest training set of c. 300 utterances. But this was still sufficient to get c. 94% accuracy.
Additional Functionality
In addition, the team added the ability to persist linguistic context (eg remember that the user was thinking about price, or a particular service).
They also added a suspend/resume feature, and a fallback intent in the parent bot, where if confidence dropped below 0.4 a fallback response was given by the bot.