CM3010 Topic 02: Relational Databases
Main Info
Title: Relational Databases
Teachers: David Lewis
Semester Taken: April 2022
Parent Module: cm3010: Databases and Advanced Data Techniques
Description
In this topic, we will look at the Entity/Relationship Models and the Relational Model. You will learn to draw E/R diagrams and interact with SQL-based Relational Database Systems. You will also encounter the concepts of joins and keys.
Key Reading
Chen: Entitry Relationship Model (1976)
The original ER Model paper.
Lab Summaries
Lab 2.301 has you model a database with an ERD, and build it in MySQL.
Lecture Summaries
2.1 Simple Relational Theory
2.001: Relational Databases
The simplest starting definition of a relational database is a datatabase that impelments the relational model.
There are problems with this though, first it’s question begging (what’s a relational model), second it’s not strictly true to current implementations. But it gives us something to start with.
A model is a way of abstracting complex, real-world data into structures that we can reason about. We take messy things and we find categories and commonalities and repeated structures that we can represent and manipulate.
Modelling happens at multiple levels. Here we mean high-level, models for how data itself works (I think he means how we interface with it). We’ll be using model in terms of more detailed structures - the data itself.
So here we have a relational model, what’s that? It derives from the word relation which here is approximately a table in the strict sense defined last topic. A row is a thing, its columns are attributes of the thing.
A relation is a combination of the definition of a table and all the values stored in it.
There are then rules about how we can manipulate the data:
- Everything is a relation:
All operations use the relational model.
All data is represented and accessed as relations.
Table and database structure is accessed and altered as relations.
The system is unaffected by its implementation. If the hardware or OS changes, the system should function as before.
If the data is distributed, it should behave as if centrally stored.
The relational model is an abstract model, it is not the entity relationship model the meaning of relation is slightly different, as we’ll see. An ER model helps model concepts - we use it in other contexts, but it’s very common to use it as part of relational database design.
The relationship in the ER mdoel is not the relation in the relational model!
Also, the relational model has almost never been purely implemented. SQL is a partial implementation, it departs from the strict model. But it’s close enough that much of the theory applies.
2.101: Drawing a Database
We start building a database by planning, and we start planning by drawing.
When we draw a relational database, we do it with the entity-relationship model. We even use the ER model for other databases too, it’s an abstract model that doesn’t match relational or other databases perfectly. We plan with the ER model and then decide the implementation.
An entity is one of the things we want to model. It can be uniquely identified.
The entity might have attributes, which are information about that entity.
A relationship is something that establishes a connection or dependency between two entities.
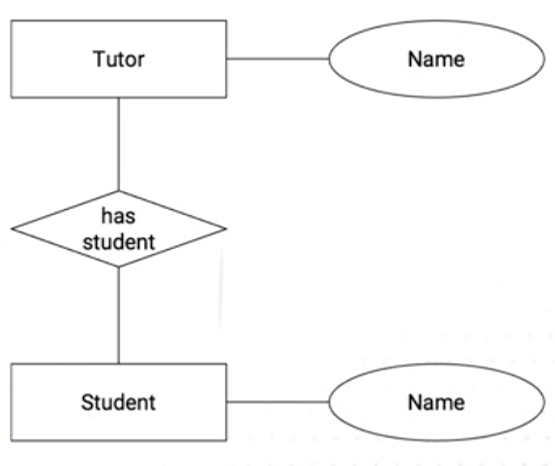
The visual language is simple to start with, though there are lots of optional information you can add.
An entity is a box, with the name of the entity inside it.
An attribute is an ellipse with the name inside.
An entity with an attribute has a line between the box and the ellipse.
A relationship is drawn as a diamond, with lines connecting two entities.
Here’s an example:
2.104 Basic SQL
We’ll use SQL, and MySQL, for relational databases. There are small differences between the RDMSs, but not huge.
In SQL we distinguish between talking about structure vs talking about data:
Working with structure we create the database itself, tables, and fields. Commands include create, drop, truncate, alter etc. This is the data definition language.
Working with data we manipulate the data itself. Commands include select, insert, update, and delete. This is the data manipulation language.
In practice this distinction isn’t very troubling as the two aspects of the language work in the same way.
In SQL the interpreter is case insensitive in most cases, but conventionally we use capitals for keywords as this helps see the query structure.
The first keyword introduces the query. For example SELECT introduces a retrieval query.
After the keyword comes the column specification, where you name the columns you want to see in the result table.
Then we introduce the table reference via FROM this gives us:
We can include constraints with the WHERE keyword. These constraints are distinct from the column specification, so to return the fields you’re using as constraints they also need to be in the column spec.
In the case of CREATE we can create multiple types of thing (tables, databases etc), so we have to specify the type of thing we’re creating and then its name. Then the rest of the query goes in brackets, the names and types of the fields. Here’s an example:
CREATE TABLE Planets (
PlanetName CHAR(8),
DayLength INT,
YearLength INT,
PRIMARY KEY (PlanetName)
);
We’ll now have a table. To ensure that we also have a relation we need to make sure that each row is unique. We can specify the primary key as a column or combination of columns that will satisfy this unique constraint.
2.2 Complex Databases
2.201 Joins
Joins are a mechanism for linking tables in queries.
The simplest means of joining the tables is just by listing them in the FROM clause of the query like so:
SELECT
Lead.name,
Rhythm.name,
Bass.name,
Drums.name
FROM
Lead,
Rhythm,
Bass,
Drums;
This is called a cross join, it will combine everything - every combination that matches the query.
So for example, if I have 7 guitarists, 12 rhythm guitarists, 8 bass, and 15 drummers, I’ll have 7 x 12 x 8 x 15 results (10,080).
This is not used much as a result.
An alternative is an inner join which constrains the results table more tightly:
SELECT
Planet.Name,
Moon.Name,
HasLiquidWater
FROM
Planet,
Moon
WHERE
Planet.Name = Moon.hasPlanet
AND
DayLength < 11;
This works because the database software recognizes that we’re doing an inner join, so doesn’t fetch everything.
But we can be more explicit and make this clearer by saying:
SELECT
Planet.Name,
Moon.Name,
HasLiquidWater
FROM
Planet
INNER JOIN
Moon
ON
Planet.Name = Moon.hasPlanet
WHERE
DayLength < 11;
The optimizer in the DB software will analyse the quickest way to carry out the join.
The other type of join is an outer join which may be a left join or right join. This will return all the rows from one of the tables, plus the matching ones from the other table. It just adds ‘null’ values in the relevant field where there was no link.
So for example if we replaced the inner join with a left join on the query above we’d get the original results plus the planets with no moon at all. Useful for finding values with no match.
2.203 More about Joins
Cardinality is concerned with how many rows in each of the tables that participate in a join match with how many rows in the other table. Often expressed as a ratio, eg 1:n, 1:1 etc.
There are three broad types:
1:n where one row in table x joins with zero or more in table y. Eg Planet:Moon, for any 1 planet there will be n moons.
1:1 remarkably rare in practice. Often artificial examples. Something like Student:Final Project, but even that will break down (retakes).
m:n many-to-many, some number in one table to some number in the other. Eg Student:Tutor.
Why do we care about cardinality as database designers? Because the implementation differs dramatically in how we model the different cardinalities.
1:n will use a Foreign Key, place the Primary Key of the table with 1 value into the table with n values.
In the ER diagram format they use in the module you can use a double line to indicate mandatory links like this:

Here the m indicates many, the double line signals the moon must have a planet.
We’d express that in the table declaration as follows:
CREATE TABLE Moons (
MoonName CHAR(20),
PlanetName CHAR(10),
Diameter INT,
PRIMARY KEY
(MoonName),
FOREIGN KEY
(PlanetName)
REFERENCES
Planets(PlanetName)
);
Note the foreign key declaration is not compulsory, but telling the DBMS that this is a foreign key gives us a lot of help down the line.
1:1 we might implement as a 1:n, or just include one element in the other’s table as a property eg in the Project:Student relationship we might decide that they are different tables with foreign key references, or just have a property in the Student table that represents the project.
m:n is the one to be wary of. The ER diagram is comfy, but we can’t model it directly in a database, we have to cheat a bit and add a new entity in the system. It’s fundamental to the relational model that individual fields are atomic, not compound. So we can’t just have a foreign keys field and then list them all.
So we add a new entity like ‘Tutor role’, for every row there will be one student, one tutor. These are called link tables. Create like this:
CREATE TABLE TutorRole (
Student VARCHAR(100),
Tutor VARCHAR(100),
PRIMARY KEY
(Student, Tutor)
);
2.3 Integrity and Keys
2.301 Integrity and Keys
One framing for this topic is “what could go wrong?” If we can identify potential errors, we can defend against them.
Take an example of a Moon with attributes: MoonName, PlanetName, and area. What could go wrong?
Maybe I labelled the PlanetName with a planet that doesn’t exist. Or I could forget to specify the planet name, perhaps the db system has defaulted to ‘NULL’. If I try to join NULL will not appear.
Maybe I specify the area to be -495. Any calculations will go wrong. We know that area should be > 0. It’s a meaningless value.
Perhaps I have a duplicate record with a slightly different value: like the same planetName and moonName with different values for area. Which is right?
Maybe I have incompatible values - a hard coded moon count might differ from the number of moons in the table attached to a planet.
Another problem, we have a moon in the moon table attached to Pluto. Now we delete Pluto in the planet table. We have an orphan moon record with an ‘invalid’ planet name.
So which of these errors are detectable and avoidable in the design, and which are we going to have to check and validate at a human level?
2.303 SQL for Joins and Keys
We’ll focus on integrity errors and constraints for now.
Integrity constraints can be applied to tables, columns, and relationships between tables.
Problem - misspelled foreign entity. Solution - Use foreign key, insert with wrong value will fail.
We can say that, eg, a moon must have a planet to orbit. So we’ll say that there must be a planet in the planet table, and the moon must reference it. This is what foreign key is for.
Problem - value is meaningless Solution - Only some values of a field are valid - CHECK column constraint
EG if we want a positive integer we can say Area INT CHECK(Area > 0) now any change that would create an area less than 0 will throw an error.
Problem - table values are inconsistent (somewhere 2 values are stored that contradict each other) Solution - Enforce uniqueness through primary keys and similar constraints
EG if we insert two moons with the same name, if the name is the primary key we won’t be able to duplicate it.
Often the primary key is auto-generated. Often useful, but you do lose the benefit of uniqueness constraint. If you do that, you may need to add other unique constraints to get this benefit. If you know that something should be unique it’s often worth enforcing it through unique constraints of some kind.
Don’t store calculatable values. For the sake of consistency avoid duplicate values that can be derived. Note that checking errors may argue the other way, but if we are focusing on consistency alone we should avoid such duplicates.
Changes should not cause inconsistency. EG the deleting the planet affecting the moon example. To avoid this we can use foreign key rules (ON DELETE CASCADE…) to dictate behaviour.
Beyond these methods there is a lot of theory around reducing the risk of inconsistent data that we’ll explore in the next topic.