CM3010 Topic 03: Reliable Databases: Data Integrity and Security
Main Info
Title: Reliable Databases: Data Integrity and Security
Teachers: David Lewis
Semester Taken: April 2022
Parent Module: cm3010: Databases and Advanced Data Techniques
Description
In this topic, we consider the question of how to keep a database reliable and consistent. We consider integrity constraints and normalization, grouping operations into transactions and user privileges.
Key Reading
Lewis Chapter 05: Designing Relational Database Systems (section on normalisation)
Codd: A Relational Model of Data for Large Shared Data Banks (1970)
Codd: Normalized Database Structure: A Brief Tutorial (1971)
Other Reading
Lecture Summaries
Intro We’re going to ask again and again, what can go wrong? and how can we mitigate?
Sources of error include:
Bad data coming in
Poor application logic
Failed database operations (maybe an error is thrown, or a system failure)
Malicious user activity
Automated integrity checking can help with bad data coming in. That doesn’t get rid of the human factor, there will always be benefit to human checking, but it’s expensive and becomes really hard depending on the scale of the data.
With application logic, normalization helps, we’ll cover this in this topic.
With failed operations, saving the database state (snapshots) is useful, but essential is the atomicity of operations which we’ll come back to.
User priviliges and security also comes in.
Integrity and the Normal Forms
3.101 Integrity
We can specify primary or unique keys to ensure rows are identifiable and to defend against errors whereby data is duplicated.
Specifying foreign keys introduces a different range of integrity constraints. It ensures references are maintainable. We can throw an error or propagate changes as we wish to ensure the database state remains consistent.
We can specify CHECK to ensure column data is valid.
Remember all these are validity checks not truth checks, they just check that the database is in a consistent state, not whether it’s correct.
There are other sorts of structures we can specify that reduce the risk of anomalies. A broad category of these are normalisation. We’ll go into the theory in this topic.
For an example, the moonCount column in the planet table is used again. We delete an erroneous moon, but now we have an inconsistent value in the mooncount and the count of moons in the moon table.
How do we get rid of that pesky mooncount column? We can just use an aggregate function. Something like:
SELECT
PlanetName,
COUNT(*) AS MoonName
FROM
Moons
GROUP BY
PlanetName;
Walks through another example with some open data about movie locations (see link above). Some issues with it:
Year of movie is listed in each row. If one is wrong you’re going to have to change it everywhere.
Location data - same location is describe differently in different places.
In both cases if you start to change it but leave the changes unfinished you’re going to end up in an inconsistent state.
3.103 Normalisation I
We’ll use this as an example:
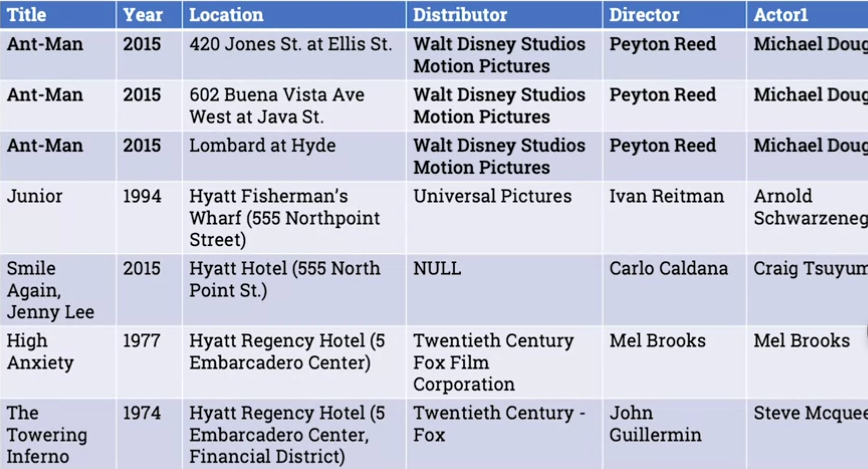
The data recurs across multiple rows. Any film that takes place in multiple locations will have multiple rows, and in each case you’ll see the same data repeated in the other columns (title, year, Distributor, Director etc.)
This repetition creates the risk of anomaly.
The same location is repeated in multiple movies, inconsistently. Similarly with distributor (see Fox).
A single table is not good at modelling lists - like Actor1, Actor2 etc. How many columns do you include? What about when you have multiple distributors?
What if the distributor is null, what if it’s part of the primary key?
If you start by modelling the real world situation with care, you’ll intuitively find yourself normalising. Normalisation is a formalization of this careful real-world modelling.
So let’s start by modelling Movie, Location, Company, Person. When things recur in multiple rows, we’re talking about entities, that have a life outside of the other entity. Eg an actor has a continued existence outside a movie. So it’s an entity in its own right.
Once we have our entities we start thinking about their relations. Their cardinality.
The way you break things down more formally in normalisation is non-loss decomposition.
non-loss decomposition is a decomposition of a single relation into two or more separate relations such that a join on the separate relations reconstructs the original.
The other central concept is that of functional dependency:
An attribute Y is said to be functionally dependent on another attribute X in the same relation if for any legal value of X there is exactly one associated value of Y.
IE it’s something that can be worked out based on something else. EG a headword and definition in dictionary. We don’t need to define the definition of a word every time we use it, we can just follow the headword’s definition.
So in the example, the actor Michael Douglas is always the actor1 if the movie is Ant Man. But we can’t invert that. So Actor if functionally dependent on Movie, but not the inverse.
Another point, there is no combination of fields that is guaranteed unique here. So we’ll introduce a film ID field, an auto-incrementing identifier, so we’re not placing artificial constraints.
This is a precursor to identifying dependencies. We can now say that film_id -> title, along with year, distributor, director, actor1 etc. That’s one large set of functional dependencies.
There may be others, if we have a company ID and year we can infer the company name for example. Film_id and Actor Number might give us a person id.
So if we have these functional dependencies what do we do with them? This is covered in the next lecture.
3.104 Normalisation II
The procedure for normalisation is to start with a given table and then check it against a progressively tighter set of requirements. Each of those sets of requirements is called a normal form. You start with the first, go to the second etc.
First Normal Form (1NF)
The table is a relation. All of its attributes are scalar values (no column contains an array or object).
To turn a table with a list of scalars in one column to first normal form, we just split up the row and have a row for each scalar.
Second Normal Form (2NF)
Normalization typically thought of as going beyond this. It depends on Heath’s Theorem which states:
A relation with attribute A,B, and C with a functional dependency A->B is equal to the join of \(\{A,B\}\) and \(\{A,C\}\)
In other words, if A-> B, B can be moved to a look-up table, and take it out of the original relation.
This gives us the second normal form
If the table is in 1NF, and every non-key attribute is irreducibly dependent on the primary key.
This is not 2NF for example:
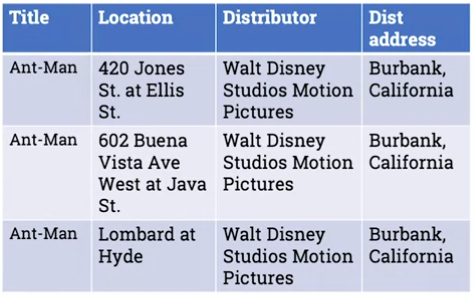
Why? Because the smallest candidate primary key is title and location, but distributor and dist address are not dependent on title and location, they’re dependent on title only. So we need to break this up and do decomposition.
We create a lookup so that dist and dist address are related to their only dependency, and the original relation becomes just title and location:

Third Normal Form (3NF)
To understand the next step we need to understand another concept, transitive dependency:
A, B, and C are attributes or sets of attributes in a relation with functional dependencies: A-> B, B-> C, so A-> C.
A-> C is defined as transitive because it is implied by A-> B and B-> C.
This gives us the third normal form
If the table is in 2NF, and every non-key attribute is non-transitively (directly) dependent on the primary key.
So in the example above, there is a dependency between Ant Man and Burbank California, but it’s not a logical dependency, it’s an indirect one. It’s only there because Disney is based there. It’s a transitive dependency.
So to get this in 3NF we need to decompose the table into another lookup, ie where the distibutors are located:

These three normal forms are essential. There are a couple of other ones, but it’s less common that they’re breached.
Boyce-Codd normal form this was added by Codd after he published the 3NF. The difference from 3NF is slight and this would be the 3NF if he’d thought of it. The gist is that all non-trivial functional dependencies depend on a superkey. See the reading for more.
Fourth Normal Form
This needs another concept: multi-valued dependency.
So far we’ve been talking about functional dependencies, which usually imply some sub-structure in the table that we want to remove and put somewhere else.
But sometimes there are structures not expressed in a functional dependency.
A and B are two non-overlapping sets of attributes in a relation. There is a multi-valued dependency if the set of values for B depends only on the values of A.
IE there’s not a mapping to just one value, but maps to a set of values. Think of a set of books that are assigned to a module. There is no functional dependency from module to book, as there’s no single value, but there is a multi-valued dependency.
This gives us the fourth normal form
If the table is in 3NF, and for every multi-valued dependency \(A \twoheadrightarrow B\), A is a candidate key.
So in the book example, we take the module and books out from a student reading list table and deconstruct to the following:
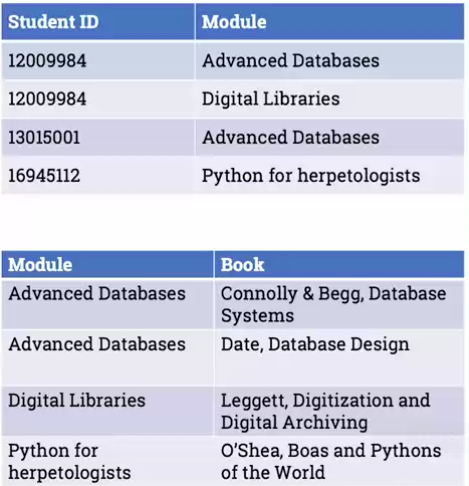
There is a fifth normal form, but it’s a bit contrived. It’s worth checking all of them, they reduce the risk of anomalies by reducing repetition. But you must check for the first 3, Boyce-Codd and 4NF.
3.2 ACID and Transactions
3.201 ACID
Normalization addresses the problem of data becoming inconsistent because the structure of the database means that the same info is recorded in multiple places.
Another problem can occur as a result of multiple interactons with the database that only make sense as a group.
Classic example of a bank account. Transferring money from A->B. We deduct the money from A and then there’s a power cut before we transfer to B. The system’s now lost the funds. Or imagine that there are two simultaneous transfers that together exceed A’s credit.
How do we avoid issues that arise due to a set of transactions needing to complete as a block?
The formalization is a set of properties called the ACID properties: Atomicity, Consistency, Isolation, and Durability.
Atomicity Groups of operations are all performed or none are.
Consistency Database is never in an inconsistent state as a result of groups of operations being processed. Intermediate states are not available to users.
Isolation If two or more groups of operations affect the same data, they can only be performed one at a time.
Durability A completed operation or group of operations will have its changes physically committed. In practice this means writing to disk in a guaranteeable way, such that if a group of operations has happened we know we can retrieve them.
3.203 Transactions and Serialisation
The mechanism for treating a group of operations as a block is called transactions.
Let’s say we have a set of operations goes through four states, the consistent start state, consistent end state, and two intermediate states that are inconsistent. If we restrict access to the intermediate states we can start to satisfy the ACID princples, in particular Isolation.
One way to do that is to lock access to the db during those intermediate states.
Another ingredient is the rollback, the ability to go back to the start state if something goes wrong. This gets us to Atomicity, if an operation in a block fails, rollback to the state immediately before the block was called.
The initial and final states should be recorded reliably. If we do that we have durability.
consistency comes from only giving access to intermediate states to operations that we know will not be affected by the known inconsistency. Only consistent initial and final states are stored.
From a developer point of view, this is fairly easy to implement through transactions.
You declare the start of a transaction with START TRANSACTION; Then any operations you put in will be treated as intermediate states before a final COMMIT; which declares the final state.
If something goes wrong we use the ROLLBACK; command to roll back to the original state.
In practice there are some issues to be aware of. If we change the structure of a database during a transaction many db systems won’t be able to roll that back.
Checkpoints, that save the database state to disk, are not as frequent as transactions. A system running multiple transactions in parallel may never reach a point where there is a straightforward consistent state to commit to disk. Though checkpoints are saved there is a complicated process of recording intermediate processes and what is queued, so that on reboot the state can be checked.
Table locking is not absolute, this gets complex when there are a lot of writes going on. In situtations that are more read-heavy it’s not so much a problem.
Here are some sample problems of what can go wrong:
Inconsistent analysis: Two transactions access the same data. One has multiple queries which give inconsistent information. So an inconsistent analysis is returned. Presents an example of reading two bank accounts while a transaction is going on.
How to avoid it? We need some locking system. We could have a write lock. So that when the mutating transaction tries to change the data its permission to get a write lock is denied, because the data is already being read. Similarly if we are mid-write there is a read lock.
But this has limitations for performance. There is an alternative where transaction 2 is given access to the old state while transaction 1 updates the new state.
If we can guarantee that the result of running the operations in parallel with our locking/cache process is the same as having run them in some sequence, then we know that they are isolated.
This is serialisability: An interleaved execution of transactions is serializable if it produces the same result as a non-interleaved execution of the same transactions.
How can we be sure of serialisability? If operations are on different data that’s safe, if they’re all reads, that’s safe. When writes come in it gets tricky (see the reading).
From a user point of view, to get the ACID guarantees you need to get a DBMS that supports them, declare your transactions. Then the DB takes care of how to implement it (through locking and failure recovery).
3.3 Security and Accounts
3.301 Malice and Accidental Damage
Some human actions can still cause trouble even if we follow all our defensive measures.
SQL injection is a common attack vector. Little Bobby Tables. There are software methods to mitigate this, and user access constraints.
We’ll focus here on controlling user privileges.
3.303 Security and User Policies with SQL
Why did the user in bobby tables have permission to restructure the database?
Users in SQL have fine grained controls available. They have permissions around creating and editing other users, databases, privileges on tables or pieces of data.
When you define your db, consider the question of what users will you have and what’s the minimum set of privileges you can grant them.
Define your user policy in advance. If you can grant users only read privileges do that.
Sometimes users will need different roles, or applications will have different logic at different times, to control access.
The syntax is as follows:
GRANT
(the privilege)
ON
(the part of the db)
TO
(the user)
EG GRANT SELECT, INSERT ON Planets, Moons TO BButi;
Now the user cannot restructure the database, so drop tables couldn’t happen.
We can use the phrase WITH GRANT OPTION at the end to mean the user can grant other users up to the same privileges they have.
We create the user like this:
CREATE USER BButi
IDENTIFIED BY 'glz2@z#'
PASSWORD EXPIRE;
There are other ways to set the password. This way the password expires as soon as they log in.
The keyword REVOKE is the opposite of GRANT
Roles have been part of the standard for a while, but are only recently implemented.
You can now do this: CREATE ROLE Astronomer;
Then: GRANT INSERT, SELECT ON Planets, Moons TO Astronomer;
Now we can just do this: GRANT Astronomer TO BButi;
The main principle is to minimise user privileges to reduce impact of error or malice.
This reduces the risk of user error or malice making serious problems. This should be part of the db design, not a post-hoc policy.